_%7B%25X@D.gif)



BabyRe
初步分析&查询
字符串先搜索,发现input,一路交叉引用向上找。
发现表和库函数
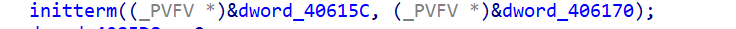

查WinApi

注意这个是在main函数前调用的
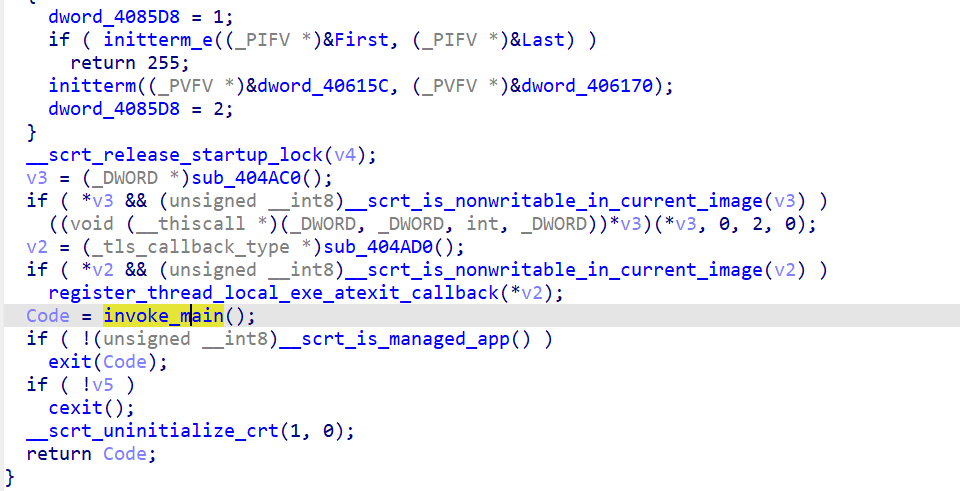
我们查看每个表,发现都有一个atexit()函数

查询可知,当程序正常终止时,调用atexit(func)指定的函数 func。对于此题来说,我们只需要知道他会在main函数结束后被调用即可。
理清程序调用顺序
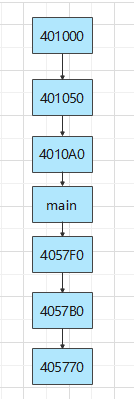
0x401000
输入
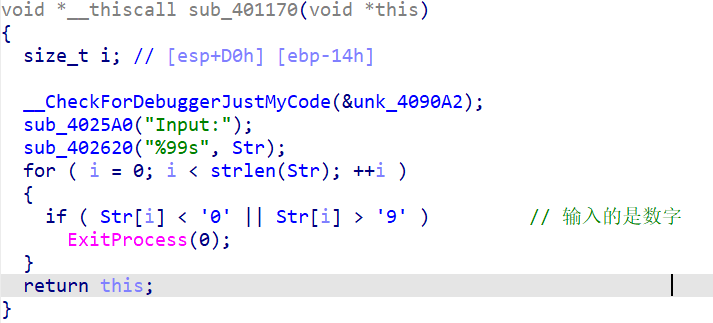
0x401050
对字符(后面base8的表)进行取反,取反结果是 ‘0’~‘7’
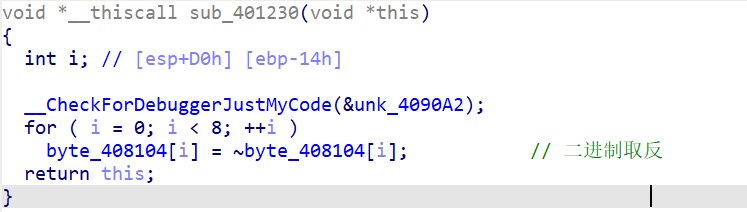
0x4010A0
IAT Hook,hook了库函数GetLastError
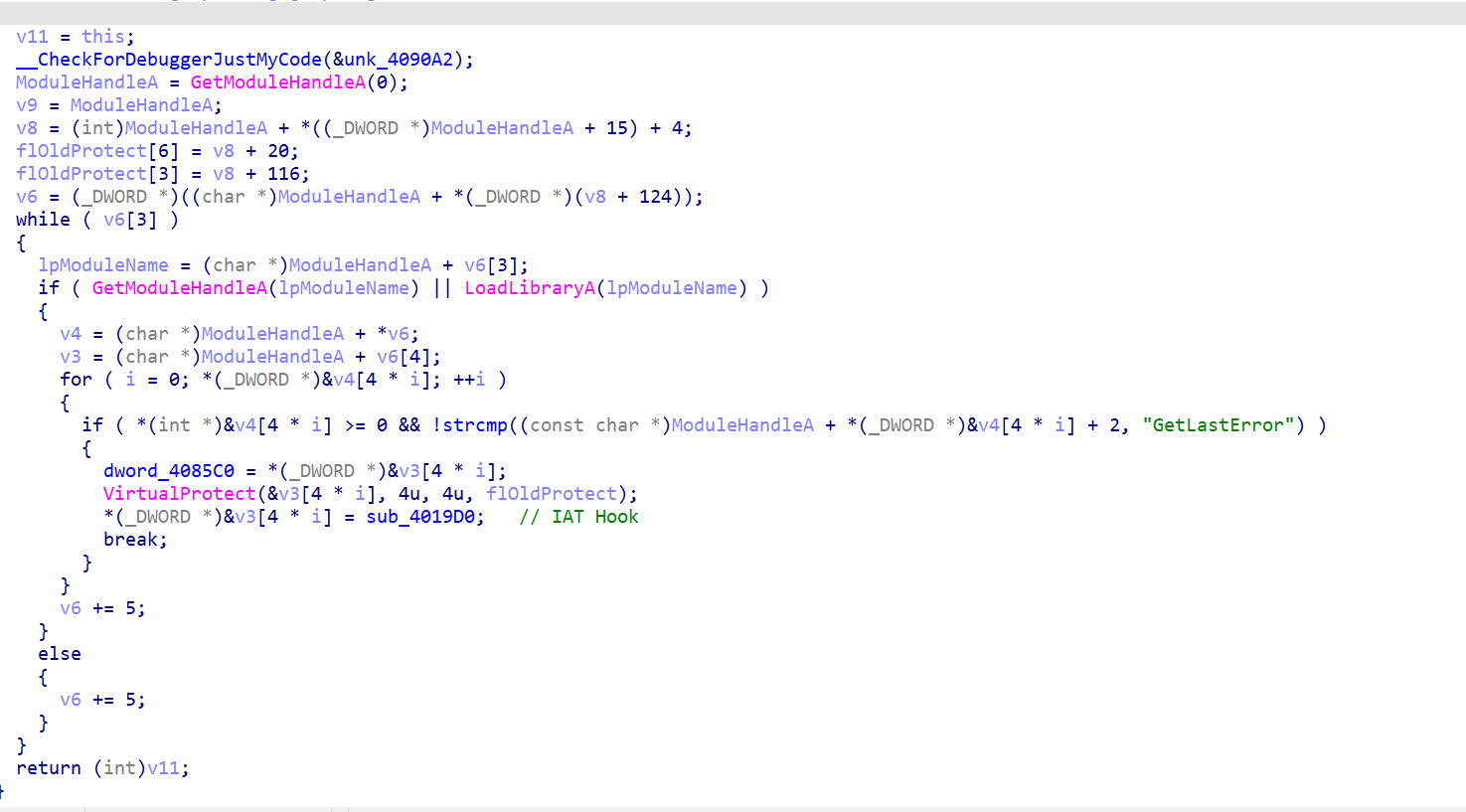
Hook函数内部

main
就一个GetLastError函数。
0x4010A0(atexit)
Base8。a1623……是base8编码且去除头尾6个字符的flag。
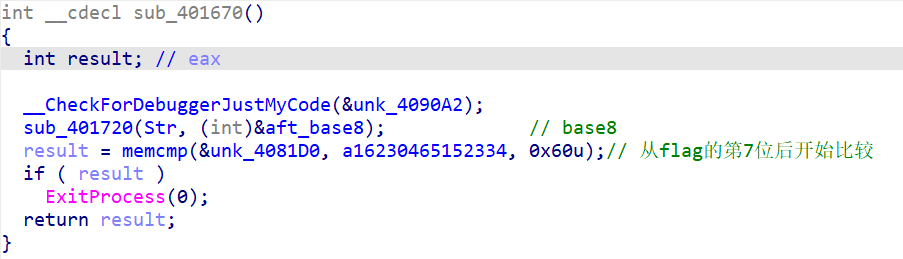
0x401050(atexit)
观察sha1的加密函数发现其对前16位进行sha1(其实就是flag前6个字符)
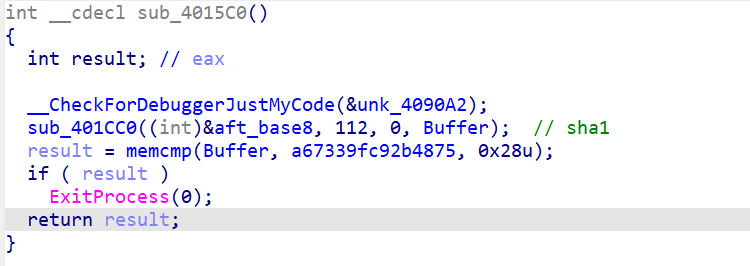
0x401000(atexit)
用flag最后6个数字作为rc4的key。加密后比较。
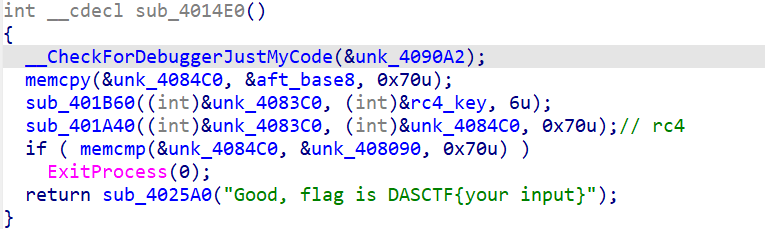
整理思路,选择解法。
优化后的解法
我们先思考RC4加密的是什么?
看函数memcpy,其拷贝了前0x70个字节,并且,这0x70个字节,只是经过base8编码后的!
如果能拿到RC4解密的结果,base8解码,再加上rc4的key,不就是flag了吗?
RC4的密码是数字且6位,爆破可行。
其次,怎么爆破呢?
我们每次爆破都能的到值,怎么确定爆破出来的是对的呢?
别忘了之前的a1623字符串,他是flag(第6~42位)经过base8后的值!我们可以用这个来和每次RC4解密后的值比较!
EXP
def decode(key):
x=[0x3F, 0x95, 0xBB, 0xF2, 0x57, 0xF1, 0x7A, 0x5A, 0x22, 0x61, 0x51, 0x43, 0xA2, 0xFA, 0x9B, 0x6F,
0x44, 0x63, 0xC0, 0x08, 0x12, 0x65, 0x5C, 0x8A, 0x8C, 0x4C, 0xED, 0x5E, 0xCA, 0x76, 0xB9, 0x85,
0xAF, 0x05, 0x38, 0xED, 0x42, 0x3E, 0x42, 0xDF, 0x5D, 0xBE, 0x05, 0x8B, 0x35, 0x6D, 0xF3, 0x1C,
0xCF, 0xF8, 0x6A, 0x73, 0x25, 0xE4, 0xB7, 0xB9, 0x36, 0xFB, 0x02, 0x11, 0xA0, 0xF0, 0x57, 0xAB,
0x21, 0xC6, 0xC7, 0x46, 0x99, 0xBD, 0x1E, 0x61, 0x5E, 0xEE, 0x55, 0x18, 0xEE, 0x03, 0x29, 0x84,
0x7F, 0x94, 0x5F, 0xB4, 0x6A, 0x29, 0xD8, 0x6C, 0xE4, 0xC0, 0x9D, 0x6B, 0xCC, 0xD5, 0x94, 0x5C,
0xDD, 0xCC, 0xD5, 0x3D, 0xC0, 0xEF, 0x0C, 0x29, 0xE5, 0xB0, 0x93, 0xF1, 0xB3, 0xDE, 0xB0, 0x70]
flag=''
j=0
c=x
s=list(range(256))
for i in range(256):
j=((j+s[i])+ord(key[i%len(key)]))%256
s[i],s[j]=s[j],s[i]
j=0
i=0
for r in c:
i=(i+1)%256
j=(j+s[i])%256
s[i],s[j]=s[j],s[i]
x=(s[i]+s[j]%256)%256
flag+=chr(r^s[x]%256)
return flag
def base8_de(num):
table=['000','001','010','011','100','101','110','111']
flag=""
for i in range(len(num)):
flag+=table[int(num[i])]
for j in range(len(flag)//8):
cur=0
for k in range(7,-1,-1):
cur+=pow(2,k)*int(flag[j*8+7-k])
print(chr(cur),end="")
if __name__ == "__main__":
for i in range(1000000):
if("16230465152334621443147115031070150320711603206314033466154344611443406614230466156344661543046" in decode(str(i).zfill(6))):
print(base8_de(decode(str(i).zfill(6))))
官方的解题思路
官方写的EXP太长,看的头疼,简单来说就是:
先通过base8和sha1爆破出flag的前6位,然后通过rc4爆破出flag的后6位,最后通过base8解密出flag中间的部分。
呵,真这么做,估计比赛结束好久了。
Xunflash学长思路
借用程序的sha1,patch一个printf出来,这样程序就能输出每次sha1爆破的值,再结合结合subprosess,与正确值比较。
真可恶,比赛结束后才爆破出来…

import subprocess
import time
for i in range(100000,1000000):
p = subprocess.Popen(["./BabyRE1.exe"], stdout=subprocess.PIPE, stdin=subprocess.PIPE)
input_data = (str(i)+"915572239428449843076691286116796614\n\n").encode()
p.stdin.write(input_data)
p.stdin.flush()
output = p.communicate()[0].decode()
# print(output[6:])
print(i,end=":")
print()
if(output[6:]=='67339fc92b4875b8c073c76994ef1ca4ce632d26'):
print(i,end="yes")
break
但是真这么解的话,要爆破两次。每次都要接近一个小时。
怎么提升爆破速度,我赛后思考这个问题?
在硬件达到极限的情况下(超频除外),增加数量。
几个人,for循环step就设置几,然后初始值改一下。几个人跑,速度快几倍。西湖论剑初赛最多8个人,理论上速度可以提高8倍。DOGE。
Dual personality
考察知识:32,64模式切换。
分析main
一片红,只能分析汇编了
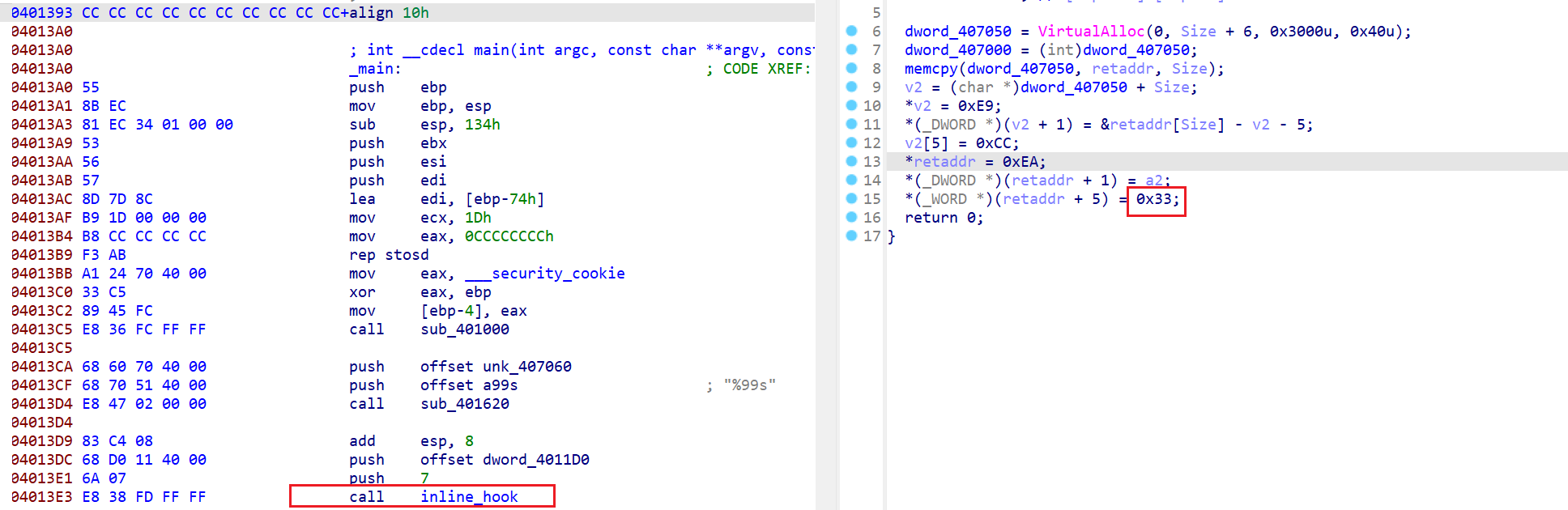
发现一个inline hook,我们可以动调一下,看看修改了啥。

一个大跳转,注意jmp far会修改CS,这里的地址IDA解析错误,应该是 0x33:0x4011D0。之前做题碰到过天堂之门(retf 0x33类型),结果比赛的时候没注意到,我是FW。不知道天堂之门的戳这里Link
jmp far,call far,retf,int等都是段间跳转指令,会同时修改CS和IP
第一次切换64位
直接Dump下来,然后IDA64分析
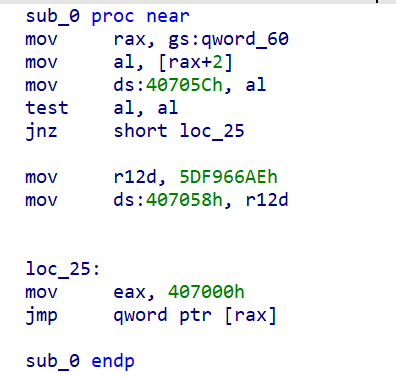
gs:60 即64位PEB

[rax+2] 即BeingDebugged的值,之后将这个值放到0x40705c中。
如果未检测到调试,修改0x407058的值。
然后重新切换返回到32位。
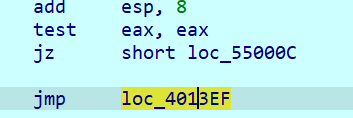
切回32位(第一次加密)
nop上下文,才勉强能F5。

循环加密相当于
for i in range(8):
str[i]+=dword_407058
dword_407058=str[i]^dword_407058
这个加密是可逆的。
第二次切换64位(第二次加密)

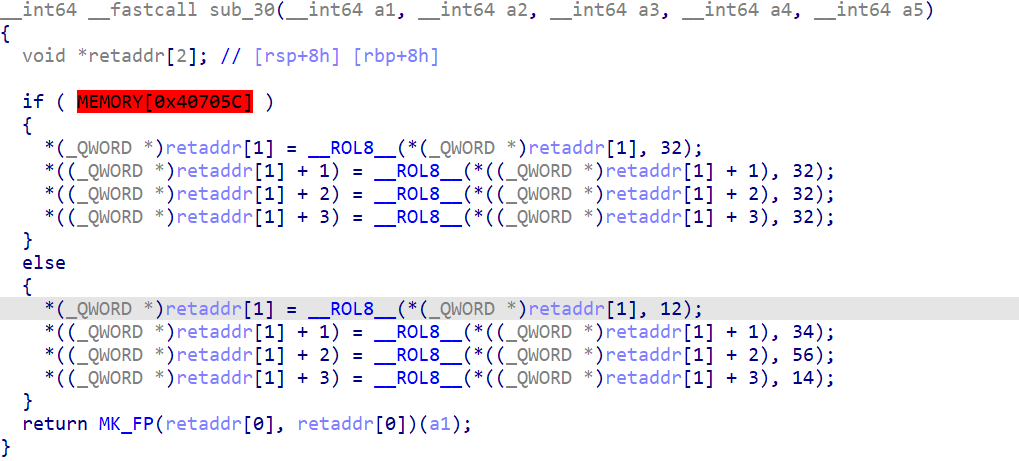
0x40705c是存储了之前BeingDebugged的值
所以下面一块代码才是真正的加密函数。
第三次切换64位

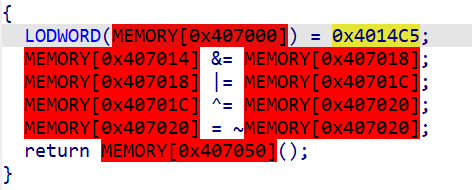
对4个值(就叫key好了)进行位运算。
未切回32位模式
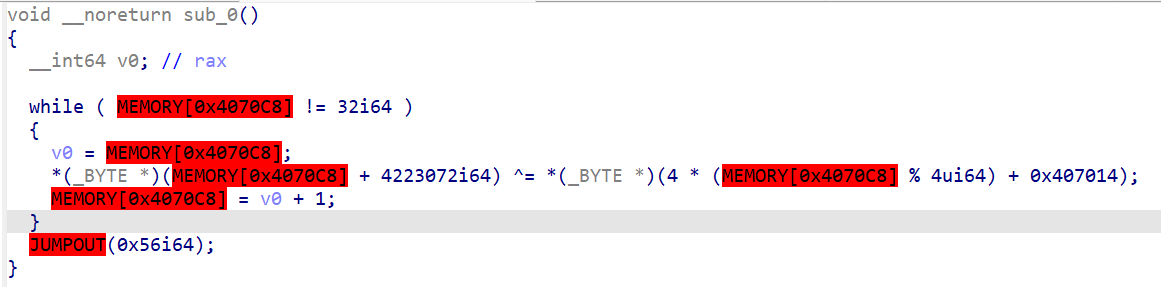
很好,还是比较简单的加密,用key进行异或加密
flag验证
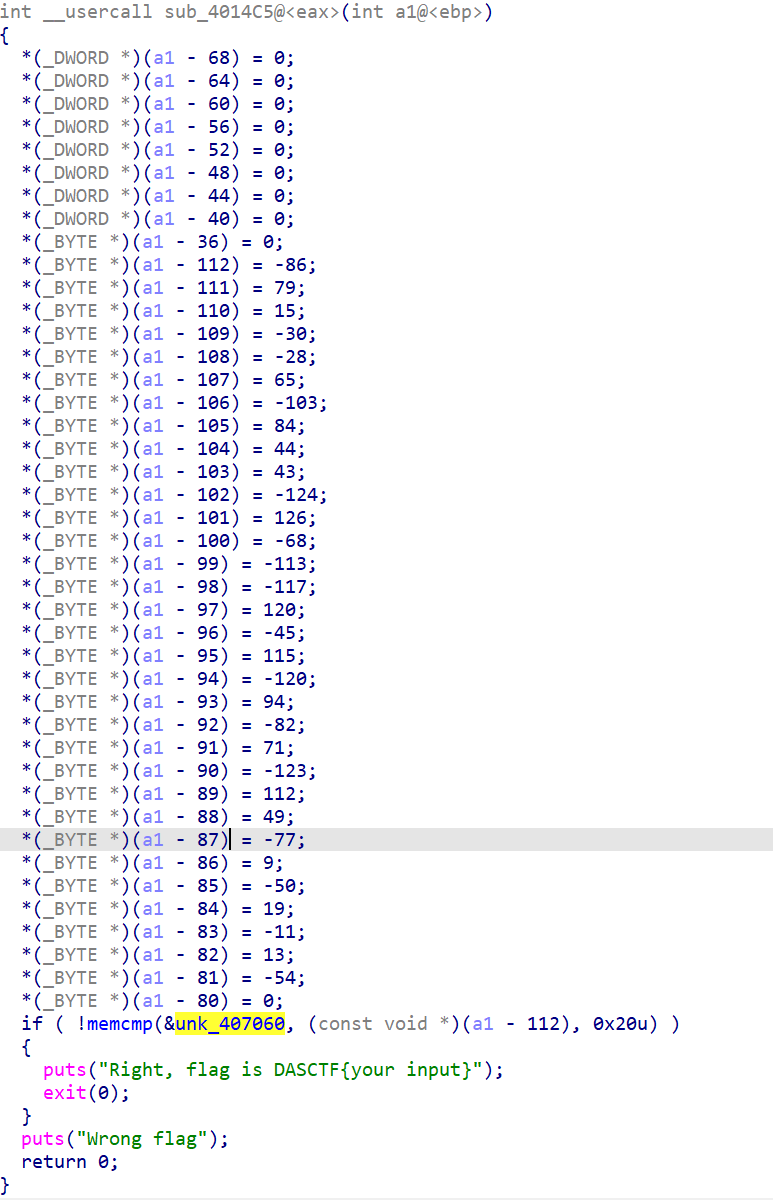
结合之前所有加密,编写EXP
def decodekey(key):
key[0]&=key[1]
key[1]|=key[2]
key[2]^=key[3]
key[3]=(~key[3])&0xff
def decode1(cipher):
for i in range(32):
cipher[i]^=key[i%4]
def ror(x,n):
return (x>>n|(x<<(64-n)&0xffffffffffffffff))&0xffffffffffffffff
if __name__ == "__main__":
cipher=[0xaa,0x4f,0x0f,0xe2,0xe4,0x41,0x99,0x54,0x2c,0x2b,0x84,0x7e,0xbc,0x8f,0x8b,0x78,0xd3,0x73,0x88,0x5e,0xae,0x47,0x85,0x70,0x31,0xb3,0x09,0xce,0x13,0xf5,0x0d,0xca]
key=[0x0000009D, 0x00000044, 0x00000037, 0x000000B5]
decodekey(key)
decode1(cipher)
cipher=[int.from_bytes(cipher[i:i+8],'little')for i in range(0,32,8)]
cipher[0]=ror(cipher[0],12)
cipher[1]=ror(cipher[1],34)
cipher[2]=ror(cipher[2],56)
cipher[3]=ror(cipher[3],14)
cipher=b''.join([i.to_bytes(8,'little')for i in cipher])
cipher=[int.from_bytes(cipher[i:i+4],'little')for i in range(0,32,4)]
x=0x5DF966AE-0x21524111
for i in range(8):
tmp=cipher[i]^x
cipher[i]=cipher[i]-x
cipher[i]&=0xffffffff
x=tmp
flagg=b''.join([i.to_bytes(4,'little')for i in cipher])
print(flagg)
#b'6cc1e44811647d38a15017e389b3f704'
Berkeley
Ebpf,第一次碰到。((好像2022虎符杯也有,有空就去复现。)
syj佬博客
看完佬的博客,我们再看main函数。

bpf_open_and_load()这个函数加载bpf字节码到内核中。
之后有个checkflag()一看就是假的。不可能这么简单…
我们就可以怀疑,加载的bpf中才包含着真正的加密与验证函数了。

根据符号表,直接找到字节码在的位置,前面sz是字节码的长度,我们dump下来,然后用Ghidra打开(需要安装插件eBPF-for-Ghidra,Github上直接搜)
使用Ghidra配合插件分析ebpf字节码
Ghidra的偏移还是难搞,估计要配合bpftools一起食用。(以后填坑)
静态分析,就只能考推理和分析了。
Label1的伪代码
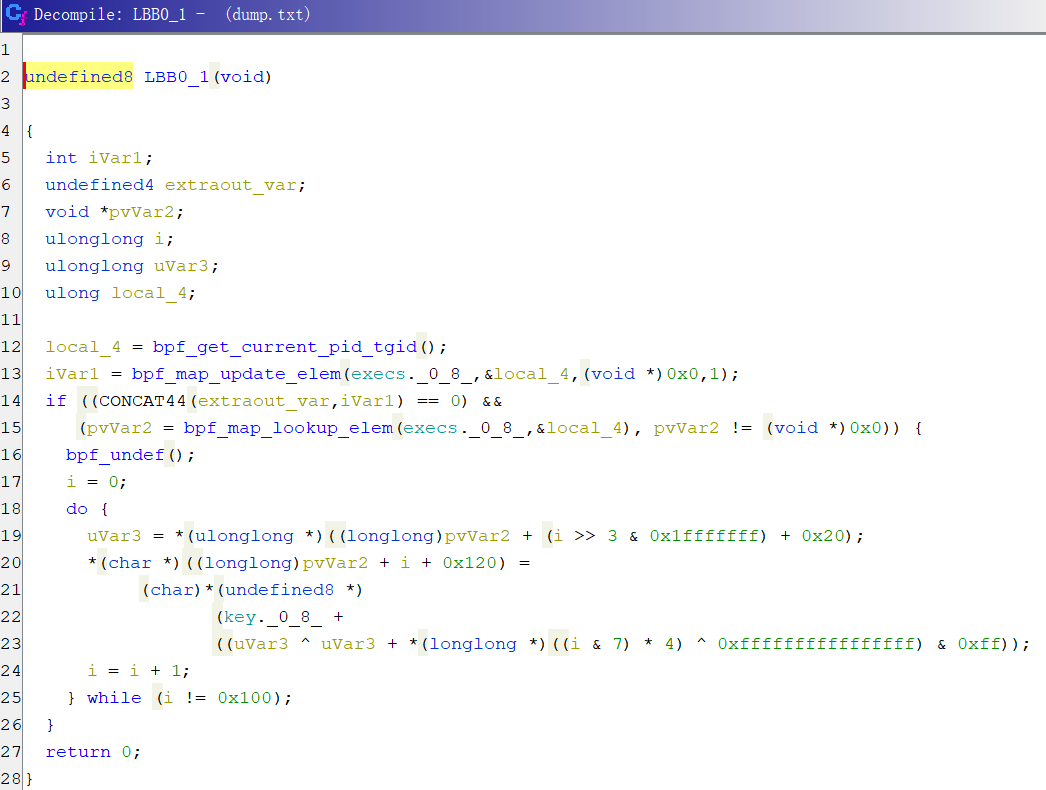
for (int i=0; i<256; i++) {
unsigned char uvar1 = input[i/8];
unsigned char uvar2 = ~(input[i/8] + arr[i%8]);
// ^0xffffffffffffffff 就是取反 &7相当于%8,我们可以推理出这是一个8字节的数组
output[i] = key[uvar1 ^ uvarc2];
}
key,cipher很容易就能找到

arr数组相比就挺难找,这偏移是一点没看懂,希望有师傅教教。
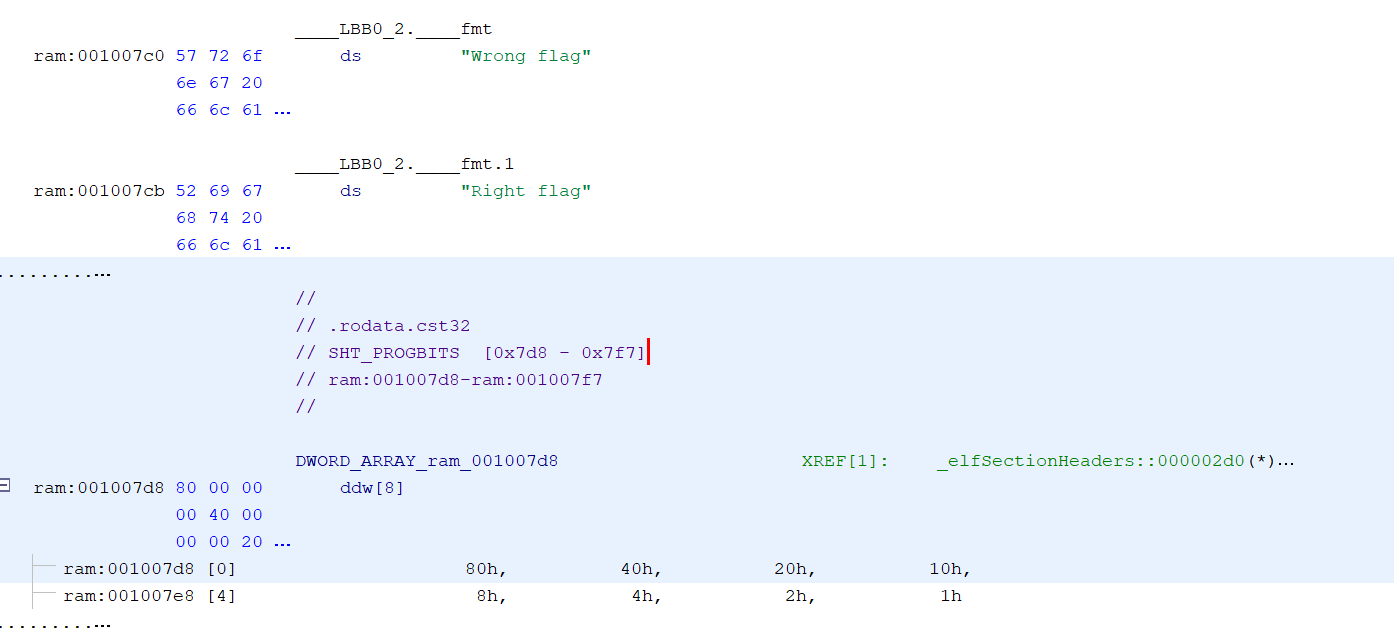
Label2的伪代码
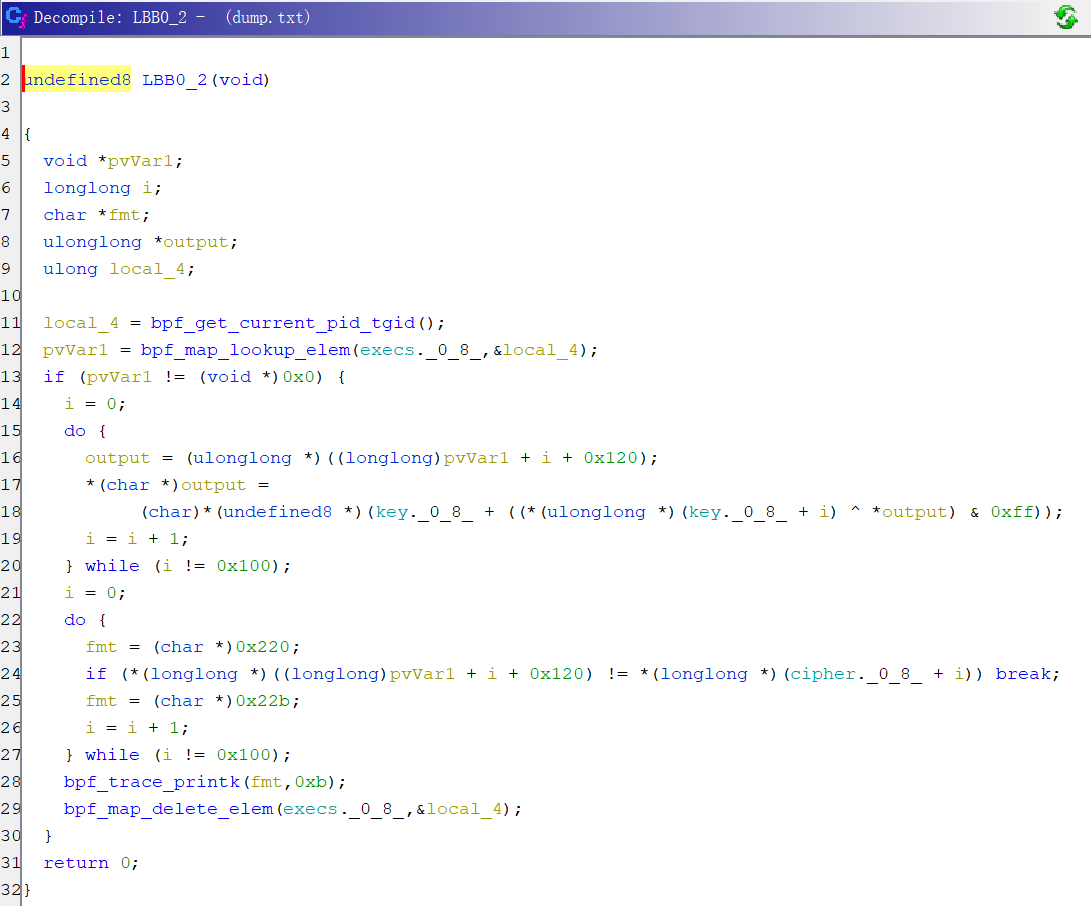
for (int i=0; i<256; i++) {
output[i] = key[output[i] ^ key[i]];
}
for (int i=0; i<256; i++) {
if(output[i]!=cipher[i]){
......
}
编写EXP
key=[0xc1, 0xd1, 0x02, 0x61, 0xd6, 0xf7, 0x13, 0xa2, 0x9b, 0x20, 0xd0, 0x4a, 0x8f, 0x7f, 0xee, 0xb9, 0x00, 0x63, 0x34, 0xb0, 0x33, 0xb7, 0x8a, 0x8b, 0x94, 0x60, 0x2e, 0x8e, 0x21, 0xff, 0x90, 0x82, 0xd5, 0x87, 0x96, 0x78, 0x22, 0xb6, 0x48, 0x6c, 0x45, 0xc7, 0x5a, 0x16, 0x80, 0xfd, 0xe4, 0x8c, 0xbf, 0x01, 0x1f, 0x4b, 0x79, 0x24, 0xa0, 0xb4, 0x23, 0x4d, 0x3b, 0xc5, 0x5d, 0x6f, 0x0d, 0xc9, 0xd4, 0xca, 0x55, 0xe0, 0x39, 0xad, 0x2b, 0xcd, 0x2c, 0xec, 0xc2, 0x6b, 0x30, 0xe6, 0x0c, 0xa8, 0x9a, 0x2f, 0xf6, 0xe8, 0xbb, 0x32, 0x57, 0xfb, 0x0b, 0x9d, 0xf2, 0x3f, 0xb5, 0xf9, 0x59, 0xe5, 0x10, 0xcf, 0x51, 0x41, 0xe9, 0x50, 0xdf, 0x26, 0x74, 0x58, 0xcb, 0x64, 0x54, 0x73, 0xab, 0xf4, 0xb2, 0x9f, 0x18, 0xf8, 0x4e, 0xfe, 0x08, 0x1d, 0x4f, 0x49, 0xd3, 0xac, 0x38, 0x12, 0x77, 0x11, 0x69, 0x07, 0x1c, 0x99, 0xb3, 0xe7, 0x3d, 0x05, 0xd8, 0xfc, 0x70, 0x46, 0x93, 0x09, 0x65, 0x89, 0xb1, 0xc6, 0x52, 0xfa, 0xd2, 0x0e, 0xa9, 0x17, 0xe3, 0x91, 0xa1, 0x68, 0x5b, 0x2a, 0xf0, 0xc3, 0x42, 0xcc, 0x29, 0xde, 0xdc, 0x85, 0x98, 0x31, 0x5c, 0xbc, 0x2d, 0xef, 0x5e, 0x7e, 0xaf, 0x67, 0x62, 0xa7, 0x56, 0x88, 0xa4, 0x43, 0x40, 0xe1, 0x37, 0x9e, 0x36, 0x76, 0x71, 0x84, 0xbd, 0x06, 0x8d, 0x47, 0x7d, 0x53, 0xd7, 0xc8, 0xce, 0x15, 0x92, 0x95, 0x4c, 0x28, 0x6d, 0x75, 0xeb, 0x7c, 0xf3, 0xbe, 0xaa, 0xb8, 0xed, 0x03, 0x3c, 0x27, 0x3e, 0x19, 0xdd, 0xa6, 0x66, 0x25, 0x1e, 0xc4, 0x6e, 0xc0, 0xe2, 0xdb, 0x3a, 0xd9, 0x81, 0xa5, 0x1b, 0xf5, 0x04, 0xae, 0xba, 0xea, 0x97, 0x83, 0x35, 0x44, 0xa3, 0x7a, 0x1a, 0xf1, 0x86, 0xda, 0x7b, 0x14, 0x72, 0x9c, 0x6a, 0x0f, 0x5f, 0x0a, 0x00 ]
cipher=[ 0xf3, 0x27, 0x47, 0x1b, 0x8f, 0x09, 0xfb, 0x17, 0x70, 0x48, 0xb0, 0x53, 0x32, 0xdb, 0xc0, 0xb8, 0x63, 0x2d, 0x40, 0x4b, 0xf5, 0x16, 0xf0, 0x35, 0xe7, 0xdf, 0xea, 0xa2, 0x9c, 0x41, 0xb3, 0x25, 0xd7, 0x0c, 0x33, 0x9c, 0x7b, 0x5a, 0xcd, 0x13, 0xbb, 0xee, 0x3e, 0x0e, 0xf2, 0xcf, 0x35, 0xda, 0xaf, 0xa2, 0x66, 0x7d, 0x38, 0x37, 0x67, 0x1e, 0x1f, 0x6b, 0x7b, 0x30, 0x0b, 0x7a, 0x02, 0xa9, 0xc8, 0x61, 0x27, 0x41, 0xdb, 0x01, 0x22, 0x31, 0x6f, 0xb6, 0xd4, 0x1b, 0x04, 0xd3, 0x94, 0xb8, 0x46, 0xc7, 0x24, 0xcf, 0xbd, 0xaf, 0x0b, 0xdc, 0x2e, 0xbb, 0xb2, 0x71, 0xf4, 0x99, 0x57, 0x36, 0xd1, 0x95, 0x52, 0x92, 0xba, 0x6d, 0xf3, 0x30, 0x50, 0x59, 0x9b, 0xea, 0x2f, 0x83, 0xdc, 0xf0, 0xde, 0x57, 0xa1, 0xac, 0xd2, 0x51, 0xa2, 0x1d, 0x59, 0xa8, 0x00, 0xb6, 0xe2, 0x65, 0x41, 0x0c, 0x4f, 0xeb, 0xf0, 0x2e, 0x58, 0x2a, 0x1f, 0xf4, 0x95, 0x72, 0x88, 0x7c, 0xa9, 0x0e, 0xcb, 0x3c, 0x42, 0xb9, 0xf3, 0x49, 0x9b, 0x52, 0x98, 0x12, 0xa3, 0x17, 0x51, 0xc0, 0x59, 0x40, 0x0a, 0xbc, 0xe8, 0x4c, 0x04, 0xfb, 0x13, 0x0a, 0x17, 0x3f, 0xe6, 0x36, 0x97, 0xdf, 0xb3, 0xe2, 0x42, 0x7f, 0xf8, 0xcc, 0x0e, 0xd1, 0x77, 0xc4, 0xa8, 0x46, 0x48, 0xe3, 0xf1, 0x0a, 0xef, 0x94, 0x56, 0x54, 0x5b, 0xca, 0xbd, 0xdd, 0x7f, 0x56, 0x47, 0xc2, 0x99, 0xfa, 0x89, 0xcc, 0xe1, 0xb9, 0x3a, 0x78, 0xe2, 0x37, 0x58, 0x01, 0x1b, 0xc3, 0x4b, 0xe6, 0x8c, 0xf3, 0xe5, 0xb6, 0x71, 0x9e, 0x63, 0xaf, 0x11, 0xce, 0x87, 0xf6, 0x6e, 0xde, 0xc8, 0xb1, 0xd0, 0x7a, 0x15, 0x6c, 0x10, 0x08, 0x99, 0x7b, 0x22, 0x55, 0x10, 0x7a, 0x82, 0x73, 0xfc, 0x62, 0xcb, 0x34, 0xa7, 0xb7, 0x62, 0xfa, 0x6b, 0x9f ]
arr=[0x80,0x40,0x20,0x10,0x8,0x4,0x2,0x1]
output=[0]*256
for i in range(0,256,8):
for j in range(32,128):
for k in range(8):
output[i+k]=key[(j^((j+arr[k])^0xFFFFFFFFFFFFFFFF))&0xff]
output[i+k]=key[output[i+k]^key[i+k]&0xff]
ok=1
for k in range(8):
if(output[k+i]!=cipher[i+k]):
ok=0
if ok==1:
print(chr(j),end="")
#71c2ac98ac8d99a2e8a95111449a7393
评论区