_%7B%25X@D.gif)



LLVM(基础篇)
所有代码都放到了我的github仓库里了
https://github.com/Fup1p1/OLLVM-Learning
LLVM概述与LLVM编译器
GCC编译器与LLVM编译器的区别
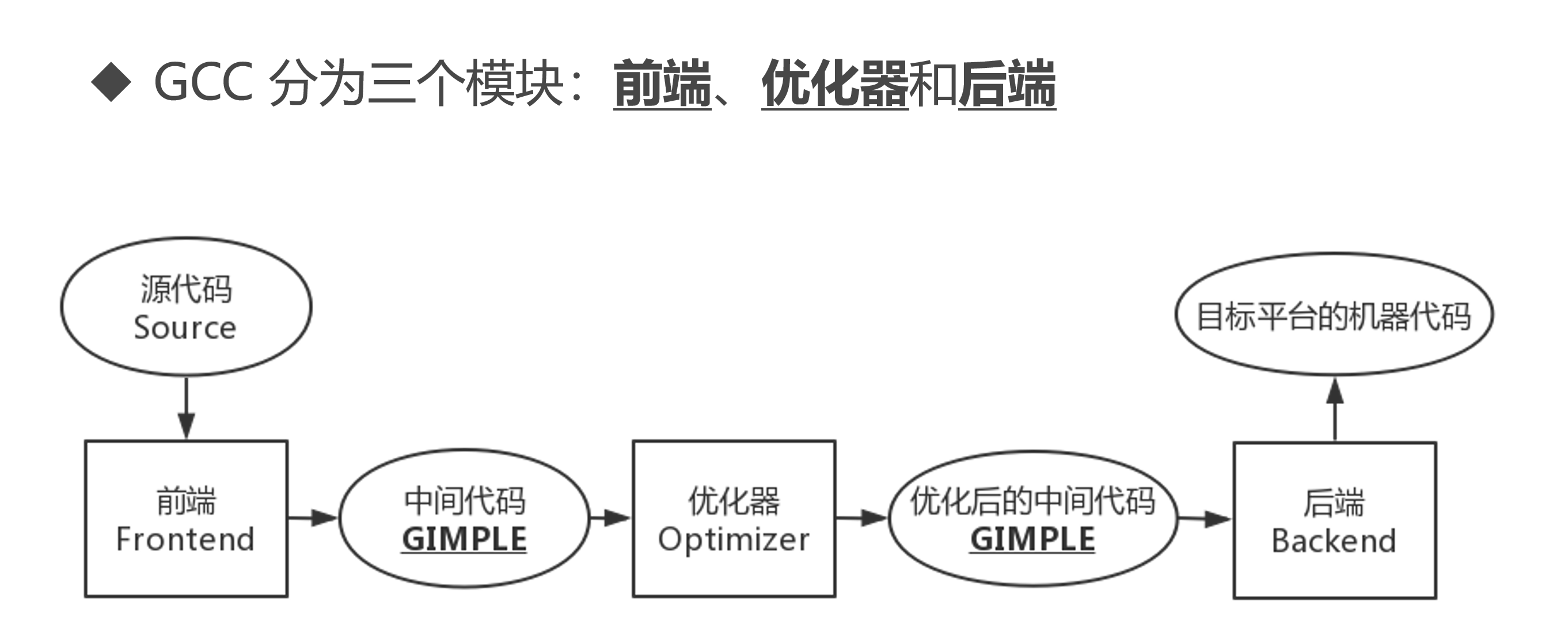
GCC编译器
LLVM编译器
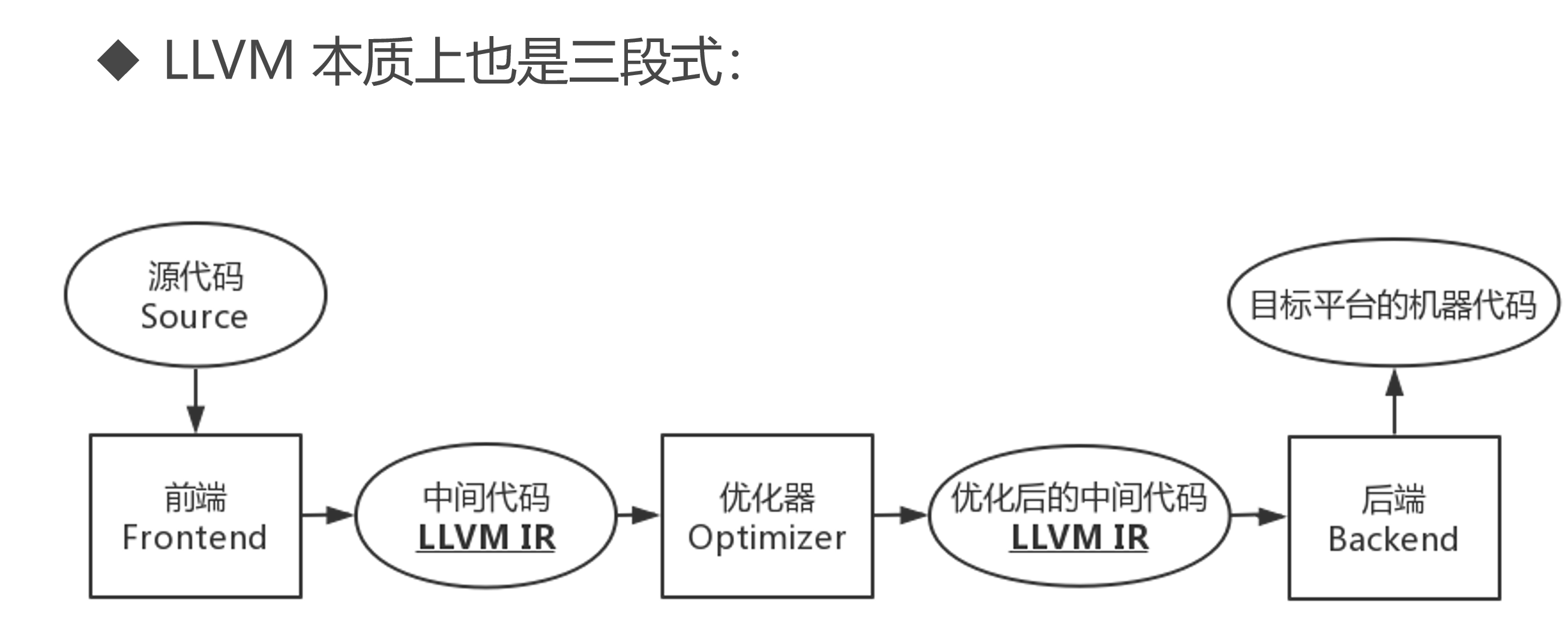
两者都是三段式编译器,主要差别就是中间代码了
LLVM 的编译流程
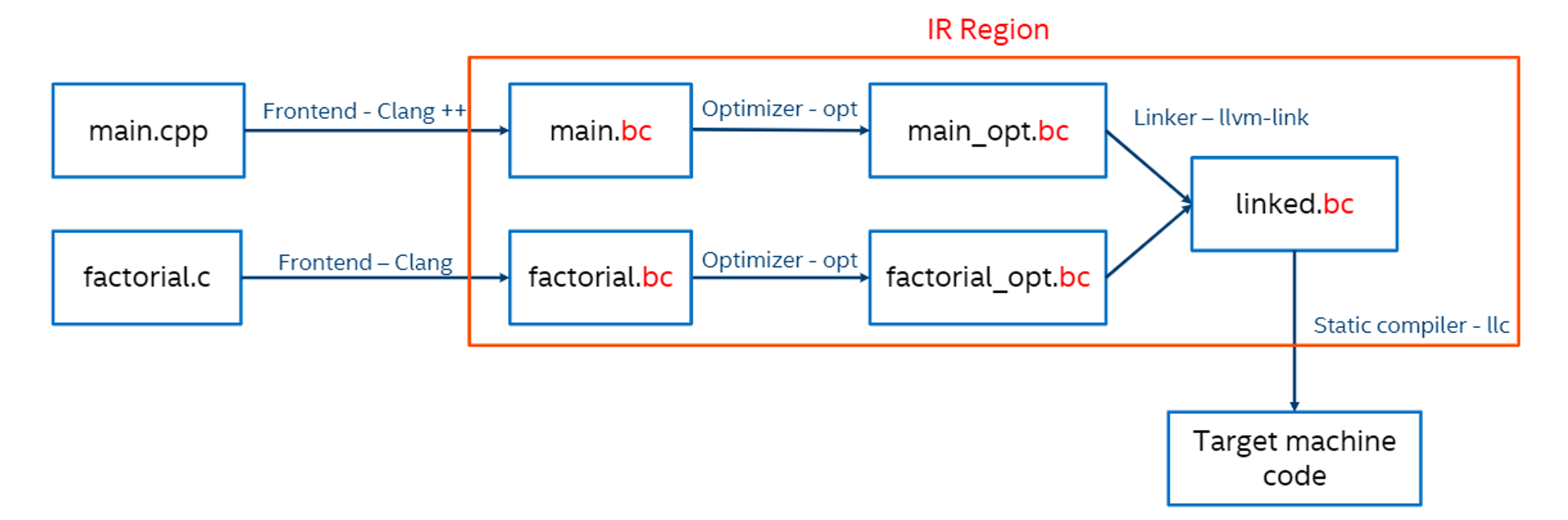
- 先通过前端Clang进行翻译,变成中间代码IR(bc即为二进制格式的LLVM IR文件)
- 再通过优化器优化,得到优化之后的中间代码文件
- 再经过LLVM IR层面的链接器llvm-link 得到一个中间代码文件
- 经过静态编译器llc,得到目标平台的机器代码
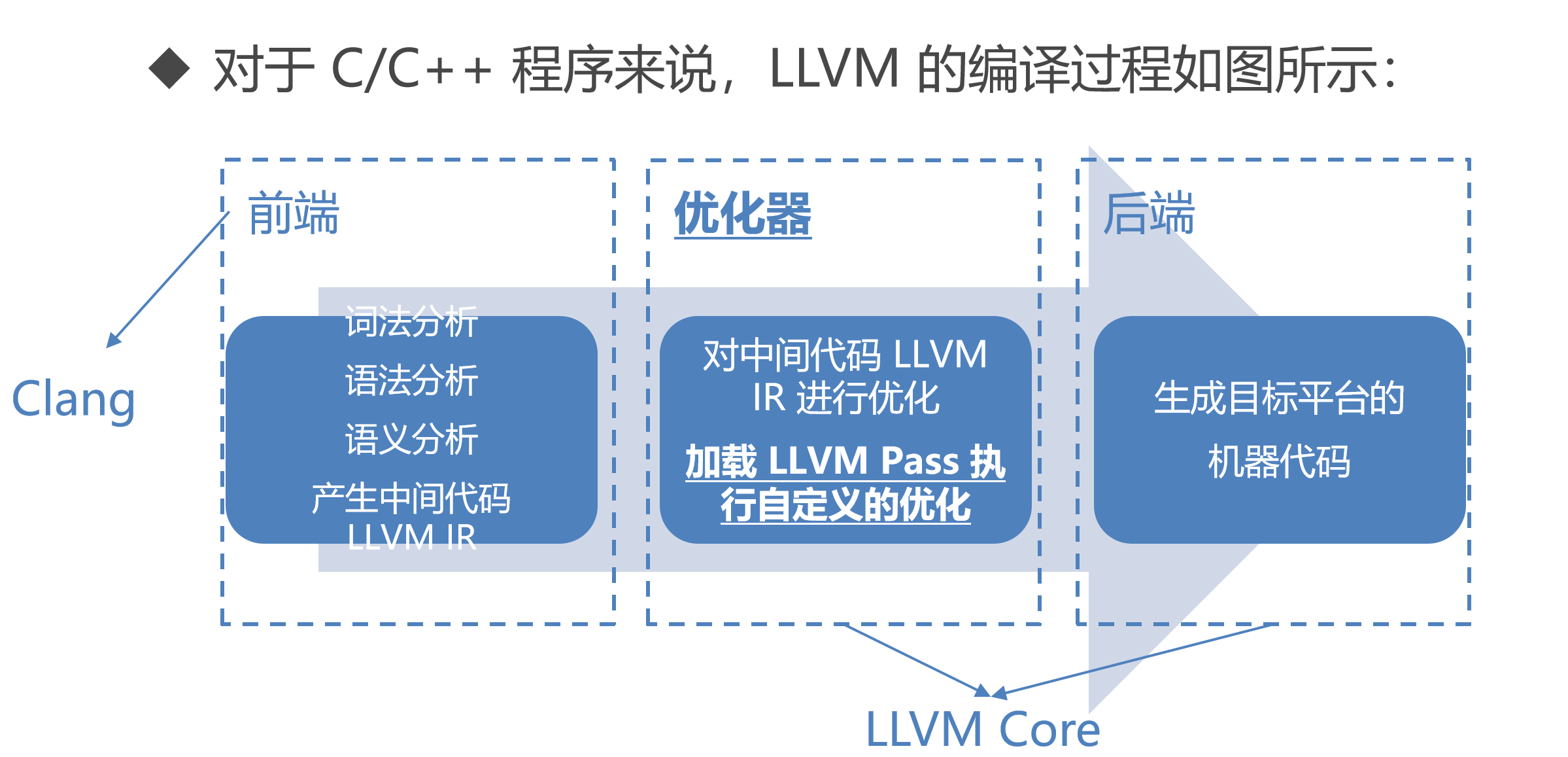
LLVM的优势
模块化

可拓展

LLVM Pass
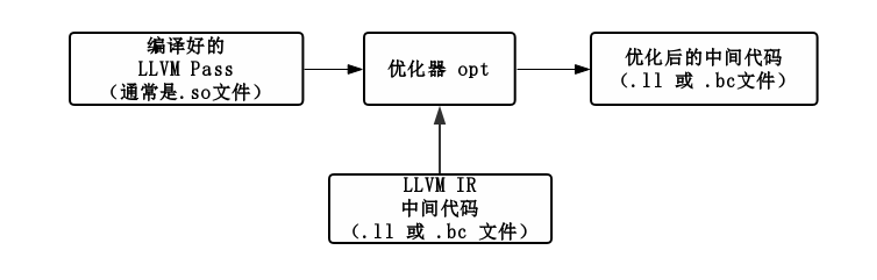
- LLVM Pass 框架是整个 LLVM 提供给用户用来干预代码优化过程的框架,也是我们编写代码混淆工具的基础。
- 编译后的 LLVM Pass 通过优化器 opt 进行加载,可以对 LLVM IR 中间代码进行分析和修改,生成新的中间代码。
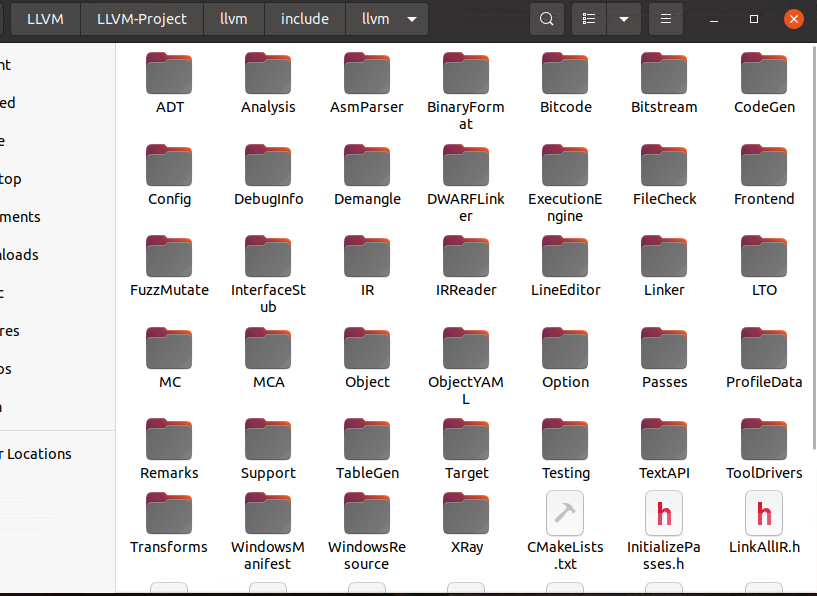
LLVM源代码目录结构
llvm/include/llvm
- llvm/include/llvm 文件夹存放了 LLVM 提供的一些公共头文件。
- 即我们在开发过程中可以使用的头文件。
llvm/lib
llvm/lib 文件夹存放了 LLVM 大部分源代码(.cpp 文件)和一些不公开的头文件
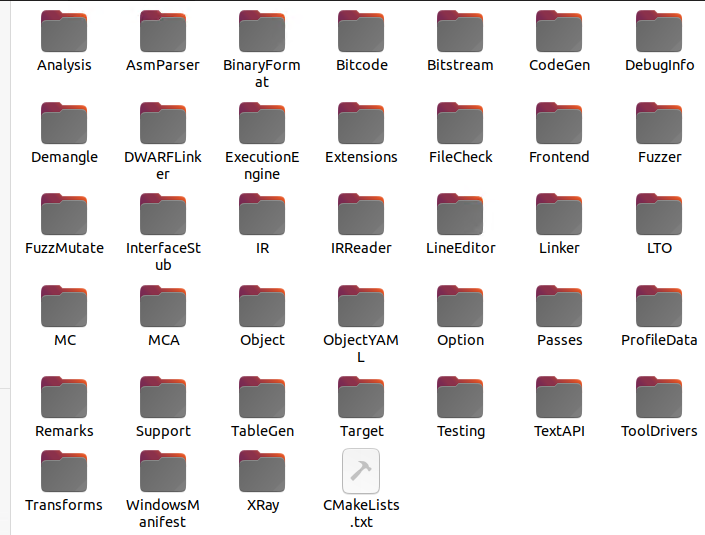
llvm/lib/Transforms
- llvm/lib/Transforms 文件夹存放所有 LLVM Pass 的源代码。
- llvm/lib/Transforms 文件夹也存放了一些 LLVM 自带的 Pass。
练手编写一个LLVM Pass,遍历程序中的所有函数
- 在设计一个新的 LLVM Pass 时,你最先要决定的就是选择 Pass 的类型。
- LLVM 有多种类型的 Pass 可供选择,包括:ModulePass(基于模块)、FuncitonPass(基于函数)、CallGraphPass(基于调用图)、LoopPass(基于环)等等。
而我们最常用到的就是 FunctionPass
FunctionPass
- FunctionPass 以函数为单位进行处理。
- FunctionPass 的子类必须实现 runOnFunction(Function &F) 函数。
- 在 FunctionPass 运行时,会对程序中的每个函数执行runOnFunction 函数。
编写步骤
- 创建一个类(class),继承 FunctionPass 父类
- 在创建的类中实现 runOnFunction(Function &F) 函数。
- 向 LLVM 注册我们的 Pass 类。
编译
- 如果选择基于 CMake 的编译方法,直接使用 CMake 进行编译即可。
- 在 Build 文件夹内可以找到编译好的 so 文件。
LLVM Pass 的加载
使用优化器 opt 将处理中间代码,生成新的中间代码:
opt -load ./LLVMObfuscator.so -hlw -S hello.ll -o hello_opt.ll
-load 加载编译好的 LLVM Pass(.so文件)进行优化
开始实践
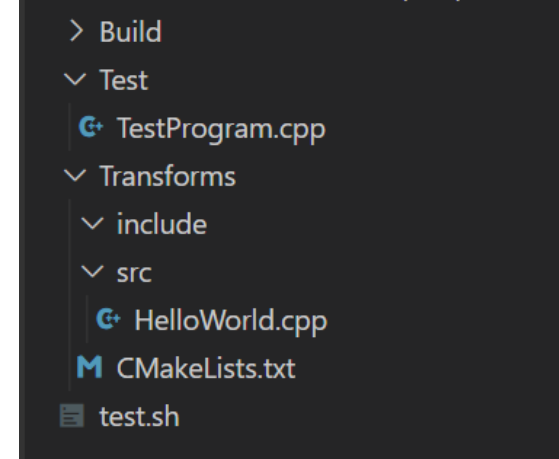
-
Build 文件夹 :存放编译后的LLVM Pass
-
Test 文件夹:存放测试程序 xxx.cpp
-
Transforms
- src 文件夹:存放整个LLVM Pass项目的源代码
- HelloWorld.cpp :HelloWorld Pass的源代码,一个Pass使用一个cpp文件实现即可
- CMakeLists.txt:整个CMake项目的配置文件
- src 文件夹:存放整个LLVM Pass项目的源代码
-
test.sh :编译LLVM Pass并且对Test文件夹中的代码进行测试
//CMakeLists.txt
project(OLLVM++) #指定项目的名称
cmake_minimum_required(VERSION 3.13.4) #指定CMake最低版本
#一些和LLVM的环境导入有关的配置
find_package(LLVM REQUIRED CONFIG)
list(APPEND CMAKE_MODULE_PATH "${LLVM_CMAKE_DIR}")
include(AddLLVM)
include_directories("./include") # 项目的包含文件夹,这样就可以包含 ./include 文件夹中的头文件
#LLVM有关的配置项
separate_arguments(LLVM_DEFINITIONS_LIST NATIVE_COMMAND ${LLVM_DEFINITIONS})
add_definitions(${LLVM_DEFINITIONS_LIST})
include_directories(${LLVM_INCLUDE_DIRS})
#向LLVM注册一个LLVMObfuscator的模块,每个模块都对应一个so文件
add_llvm_library( LLVMObfuscator MODULE
src/HelloWorld.cpp
)
//test.sh
cd ./Build
cmake ../Transforms
make
cd ../Test
clang -S -emit-llvm TestProgram.cpp -o TestProgram.ll
opt -load ../Build/LLVMObfuscator.so -hlw -S TestProgram.ll -o TestProgram_hlw.ll
clang TestProgram_hlw.ll -o TestProgram_hlw
./TestProgram_hlw
// HelloWorld.cpp
#include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
namespace{ //自定义命名空间
class HelloWorld :public FunctionPass{ //继承FunctionPass类
public :
static char ID;
HelloWorld():FunctionPass(ID){} //构造函数
bool runOnFunction(Function &F);
};
}
bool HelloWorld::runOnFunction(Function &F){
//todo
outs()<<"Hello,"<<F.getName()<<"\n"; //这里通过outs()来获取整个LLVM的输出流,用法和cout一样。 我们可以用过getName去获取到每一个函数的名称。
}
char HelloWorld::ID=0;
static RegisterPass<HelloWorld>X("hlw","My first line of LLVM Pass"); //向LLVM注册我们的pass 其中X()中的第一个参数是指定LLVM Pass的参数 ,这样再使用opt加载这个so文件的时候,用这个参数来指定用哪个Pass来优化,第二个参数就是对Pass的描述。
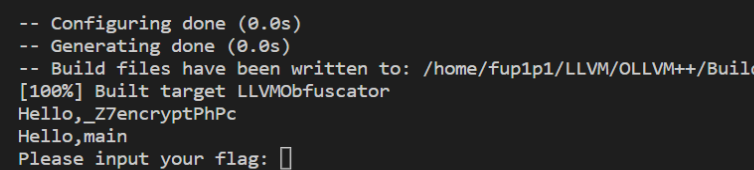
运行结果
LLVM IR 概述
什么是LLVM
- LLVM IR 是一门低级编程语言,语法类似于汇编
- 任何高级编程语言(如C++)都可以用 LLVM IR 表示
- 基于 LLVM IR 可以很方便地进行代码优化
LLVM的两种表示方法
这个前面接触过,一个是人类可阅读的文本形式,后缀为.ll,一个是易于机器处理的二进制格式.bc
.ll 和 .bc 可以通过 llvm-dis 和llvm-as 这两个llvm自带的工具进行转换
LLVM IR 结构
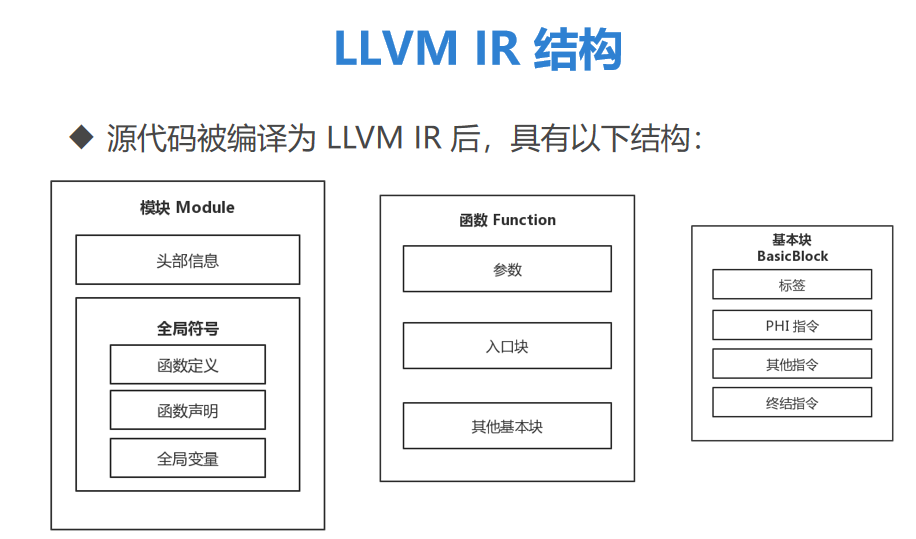
模块 Module

函数
入口块可以跳转其他基本块执行
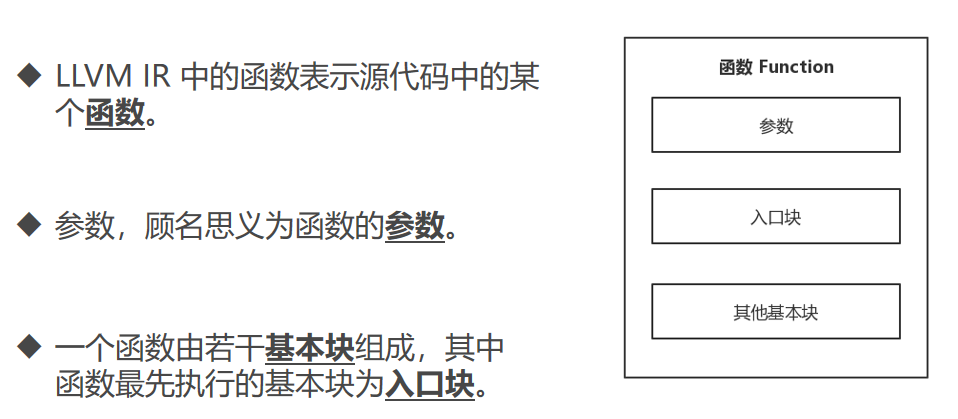
基本块

- 控制流平坦化 :以函数为基本单位的混淆:
- 虚假控制流 :以基本块为基本单位的混淆:
- 指令替换 :以指令为基本单位的混淆:
LLVM IR 的常用指令
终结指令 Terminator Instructions
基本块的最后一个指令,通常是跳转指令或者返回值了
ret 指令
函数的返回指令,对应 C/C++ 中的 return。

实例

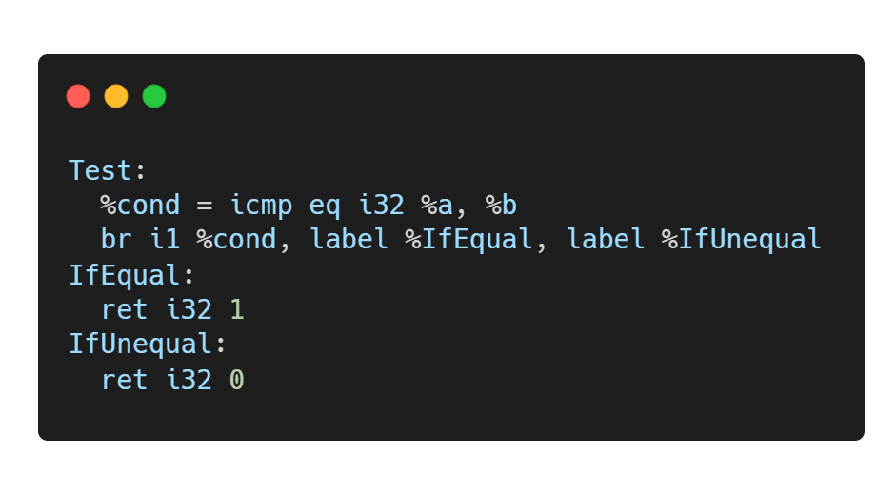
br 指令
- br 是”分支”的英文 branch 的缩写,分为非条件分支和条件分支,对应 C/C++ 的 if 语句。
- 无条件分支类似于x86汇编中的 jmp 指令,条件分支类似于x86汇编中的 jnz, je 等条件跳转指令。

icmp是一个比较指令 会比较 a和b的值
如果 cond 为true = => IfEqual cond为false ==> IfUnequal
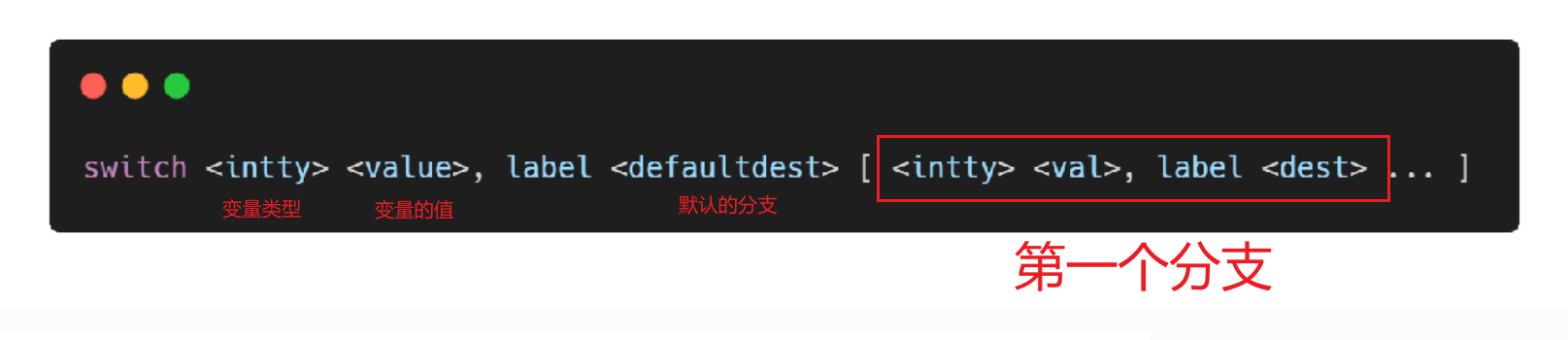
switch指令
分支指令,可看做是 br 指令的升级版,支持的分支更多,但使用也更复杂。对应 C/C++ 中的 switch。

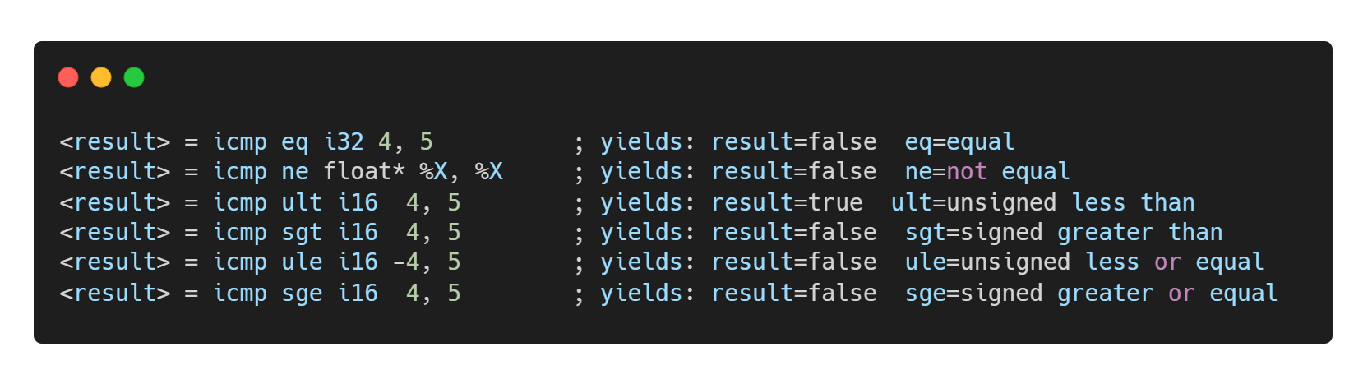
补充icmp指令
- 整数或指针的比较指令。
- 条件 cond 可以是 eq(相等), ne(不相等), ugt(无符号大于)等等。
ty是比较数的类型

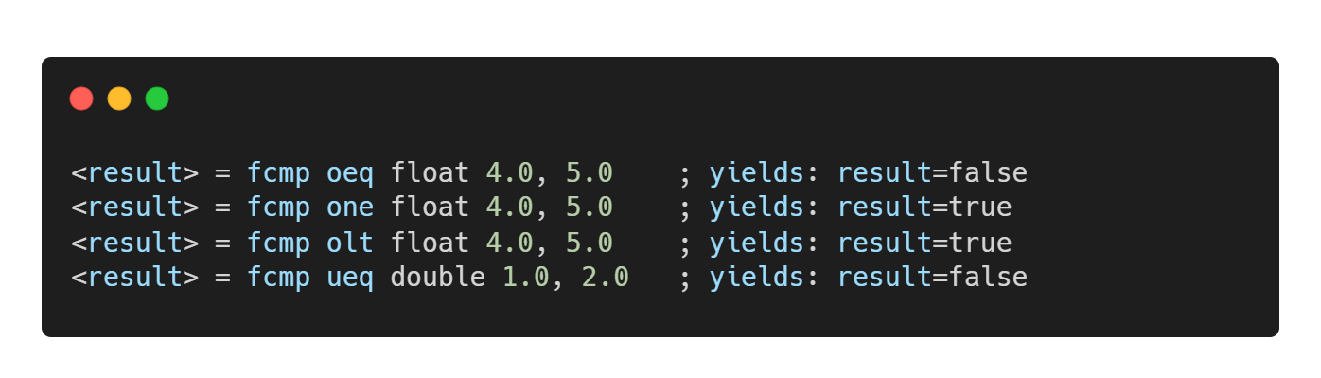
fcmp 指令
- 浮点数的比较指令
- 条件 cond 可以是 oeq(ordered and equal), ueq(unordered or equal), false(必定不成立)等等。
- ordered的意思是,两个操作数都不能为 NAN

二元运算 Binary Operations
加减乘除等指令,就和x64汇编很像了
add
整数加法指令,对应 C/C++ 中的“+”操作符,类似x86汇编中的 add 指令。


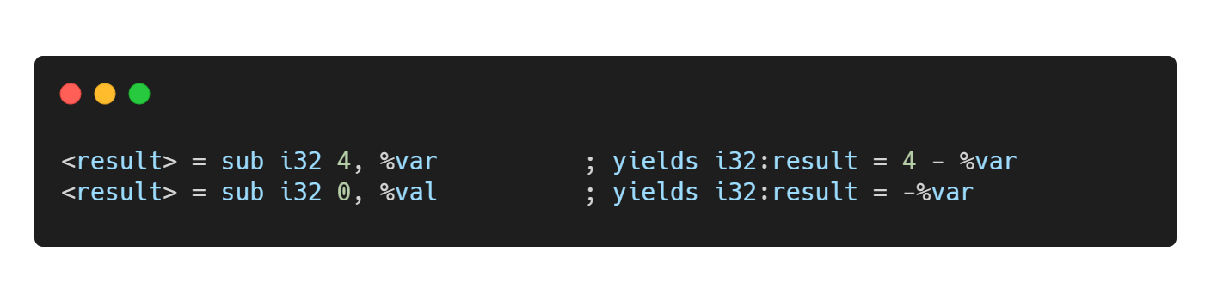
sub指令
整数减法指令,对应 C/C++ 中的“-”操作符,类似x86汇编中的 sub 指令。

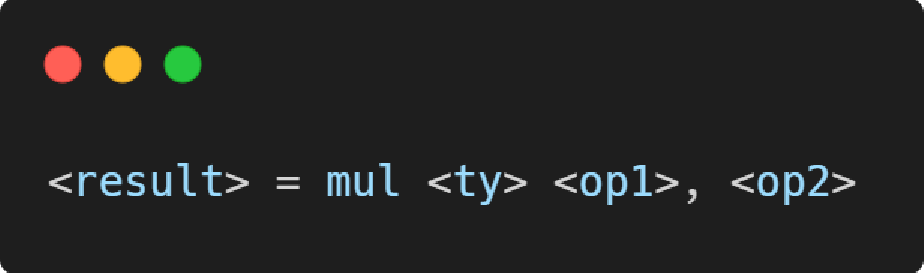
mul指令
整数乘法指令,对应 C/C++ 中的“*”操作符,类似x86汇编中的 mul 指令。

udiv指令
无符号整数除法指令,对应 C/C++ 中的“/”操作符。如果存在exact关键字,且op1不是op2的倍数,就会出现错误。


sdiv 指令
有符号整数除法指令,对应 C/C++ 中的“/”操作符。


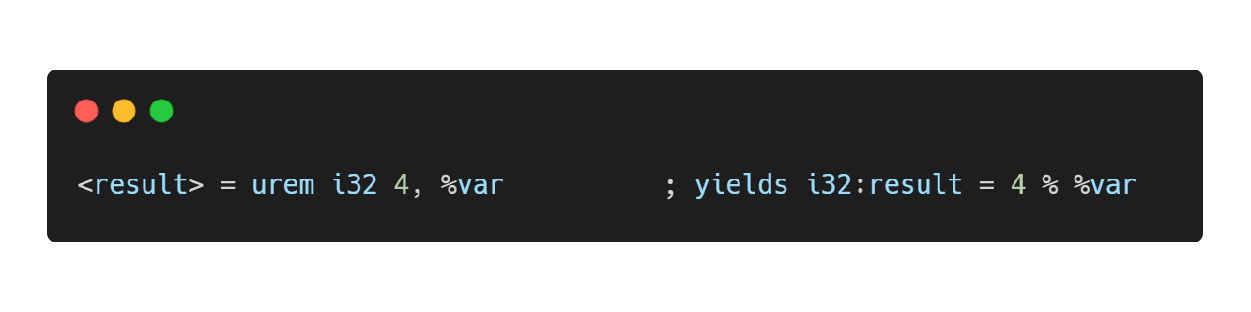
urem 指令
无符号整数取余指令,对应 C/C++ 中的“%”操作符。

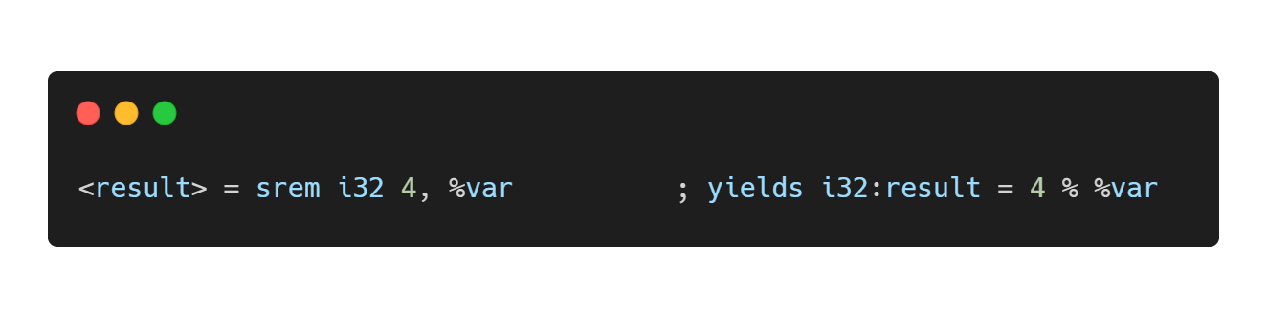
srem指令
有符号整数取余指令,对应 C/C++ 中的“%”操作符。

按位二元运算 Bitwise Binary Operations
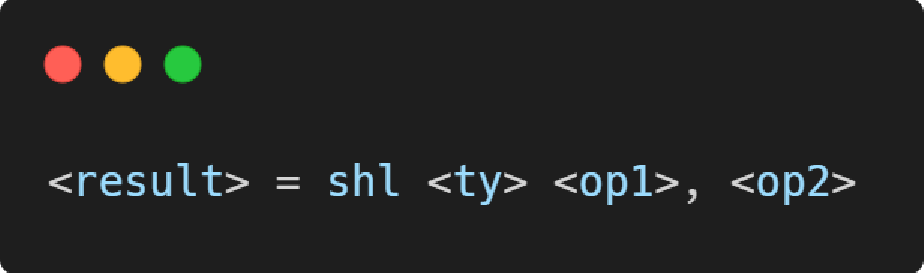
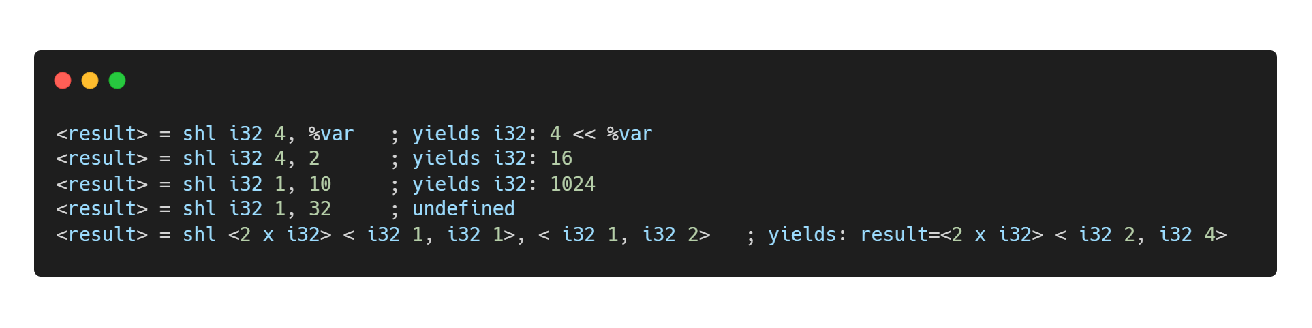
shl指令
整数左移指令,对应 C/C++ 中的“<<”操作符,类似x86汇编中的 shl 指令。
lshr指令
整数逻辑右移指令,对应 C/C++ 中的“>>”操作符,右移指定位数后在左侧补0。


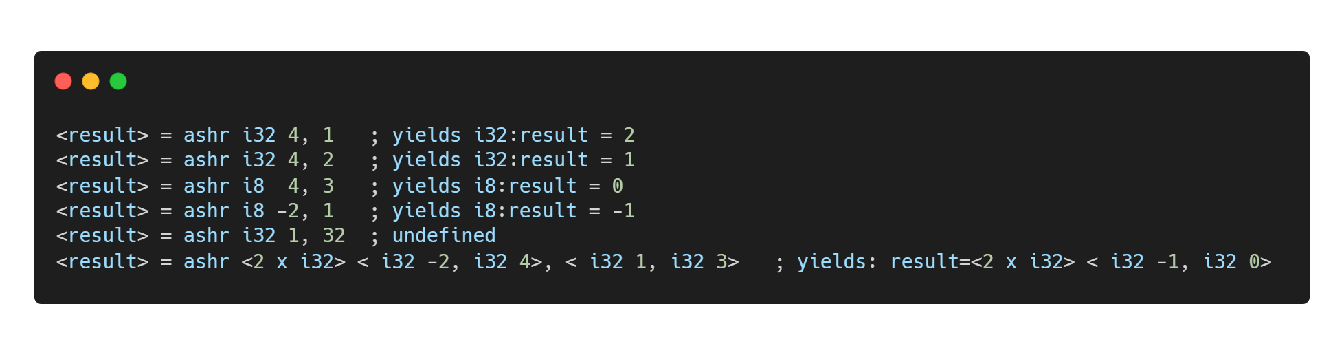
ashr
整数算数右移指令,右移指定位数后在左侧补符号位(负数的符号位为1,正数的符号位为0)。

and指令
整数按位与运算指令,对应 C/C++ 中的“&”操作符。


or指令
整数按位或运算指令,对应 C/C++ 中的“|”操作符。


xor指令
整数按位异或运算指令,对应 C/C++ 中的“^”操作符。

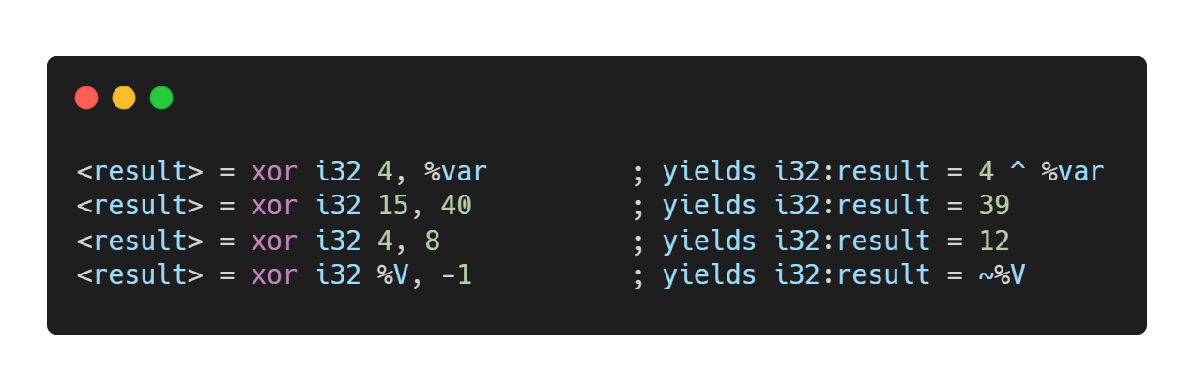
内存访问和寻址操作 Memory Access and Addressing Operations
静态单赋值
- 在编译器设计中,静态单赋值(Static Single Assignment, SSA),是 IR 的一种属性。
- 简单来说,SSA 的特点是:在程序中一个变量仅能有一条赋值语句。
- LLVM IR 正是基于静态单赋值原则设计的。
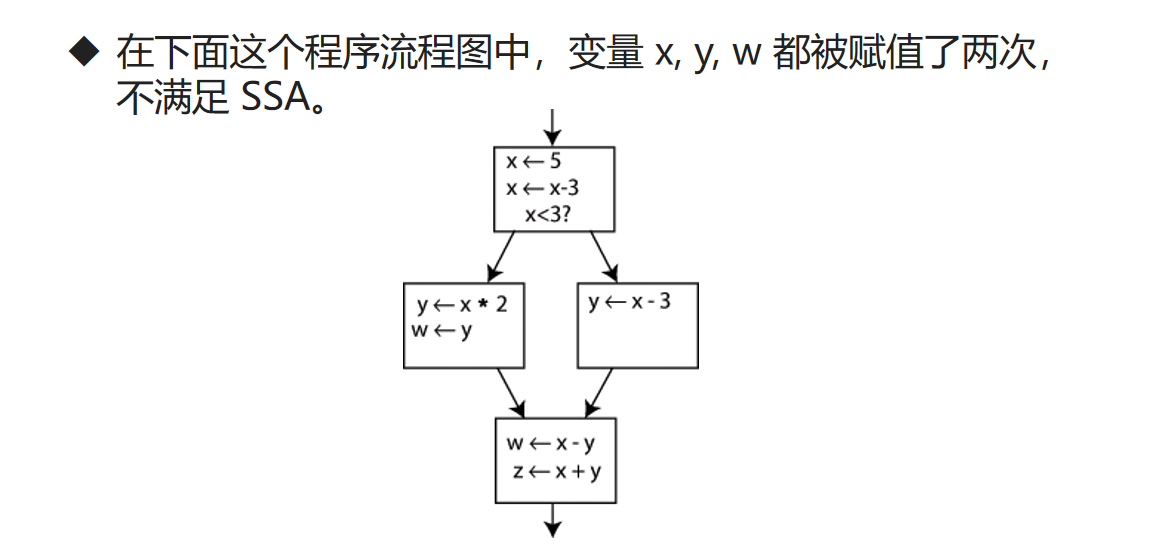
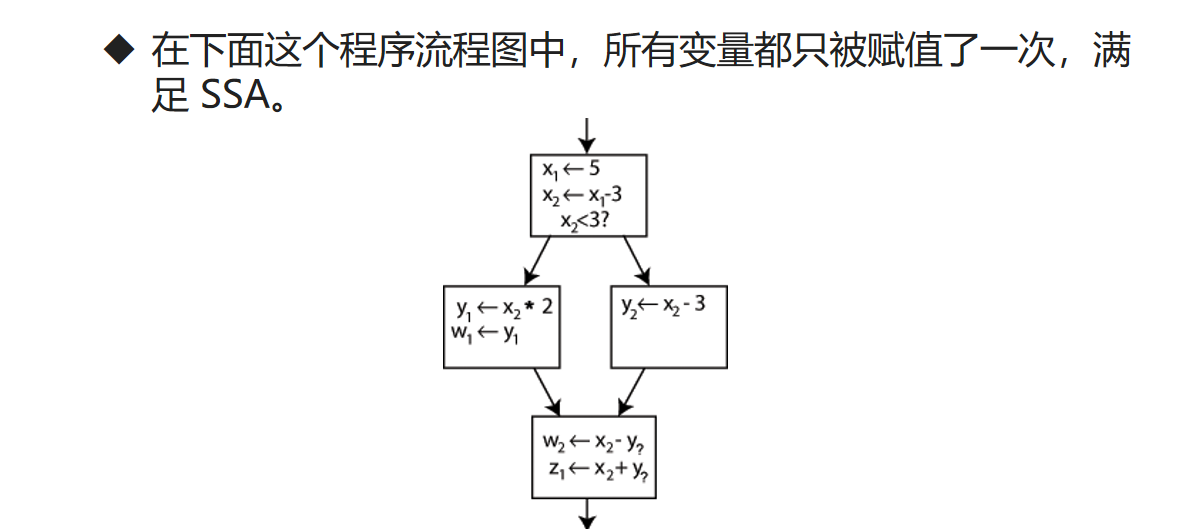

假如C++是基于静态单赋值原则的,那么左图就不符合。但是修改为右图就符合SSA原则了。
alloca指令
- 内存分配指令,在 栈中分配一块空间并获得指向该空间的指针,类似于 C/C++ 中的 malloc 函数。


store指令
- 内存存储指令,向指针指向的内存中存储数据,类似于 C/C++ 中的指针解引用后的赋值操作。

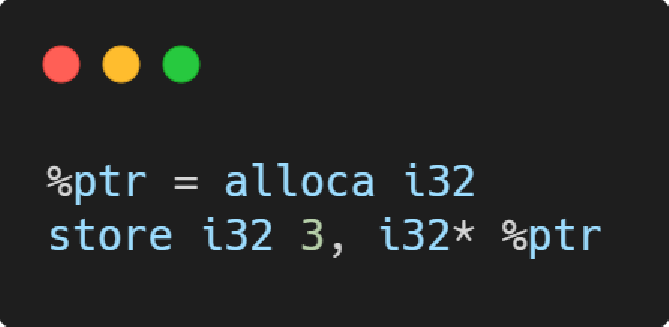
load指令
- 内存读取指令,从指针指向的内存中读取数据,类似于 C/C++ 中的指针解引用操作。


类型转换操作 Conversion Operations
trunc … to 指令(大转小)
- 截断指令,将一种类型的变量截断为另一种类型的变量。对应 C/C++ 中大类型向小类型的强制转换(比如 long 强转 int)


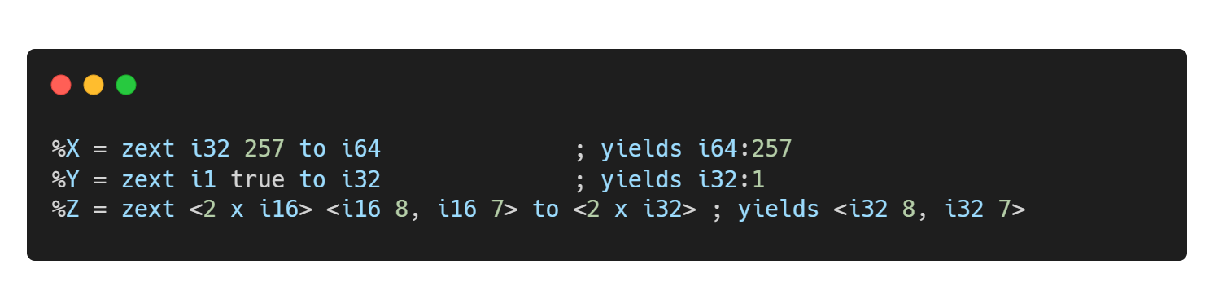
zext … to 指令 (小转大)
- *** 零拓展(Zero Extend)指令,将一种类型的变量拓展为另一种类型的变量,高位补0。对应 C/C++ 中小类型向大类型的强制转换(比如 int 强转 long)

sext … to 指令 (符号位扩展)
- 符号位拓展(Sign Extend)指令,通过复制符号位(最高位)将一种类型的变量拓展为另一种类型的变量。


其他操作 Other Operations
phi 指令
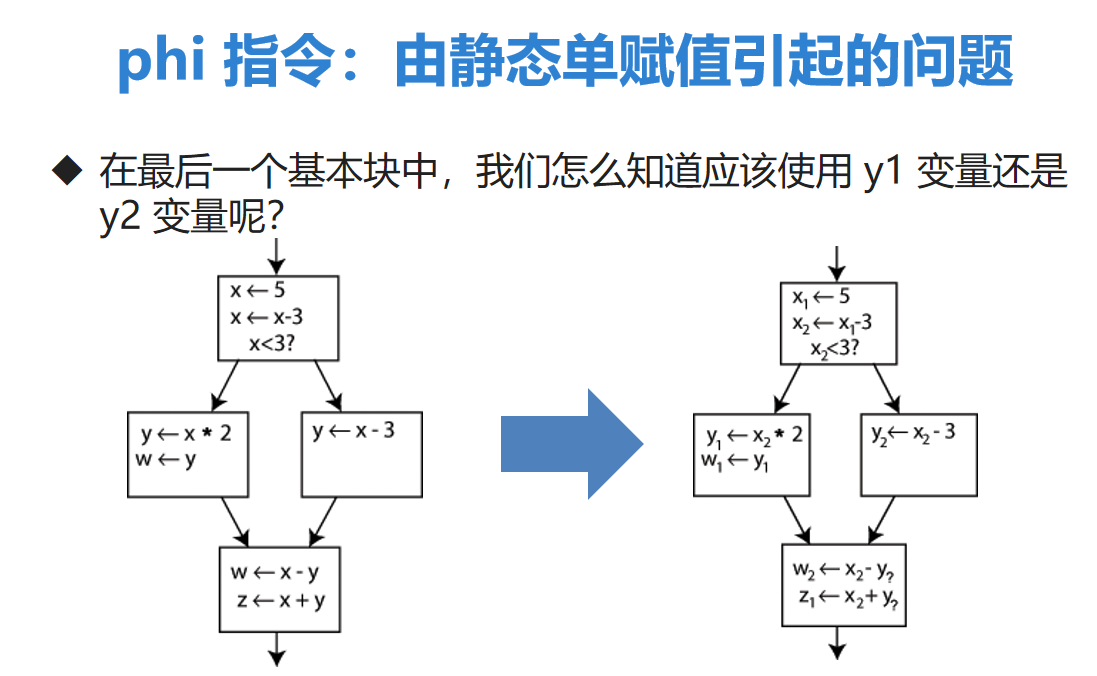
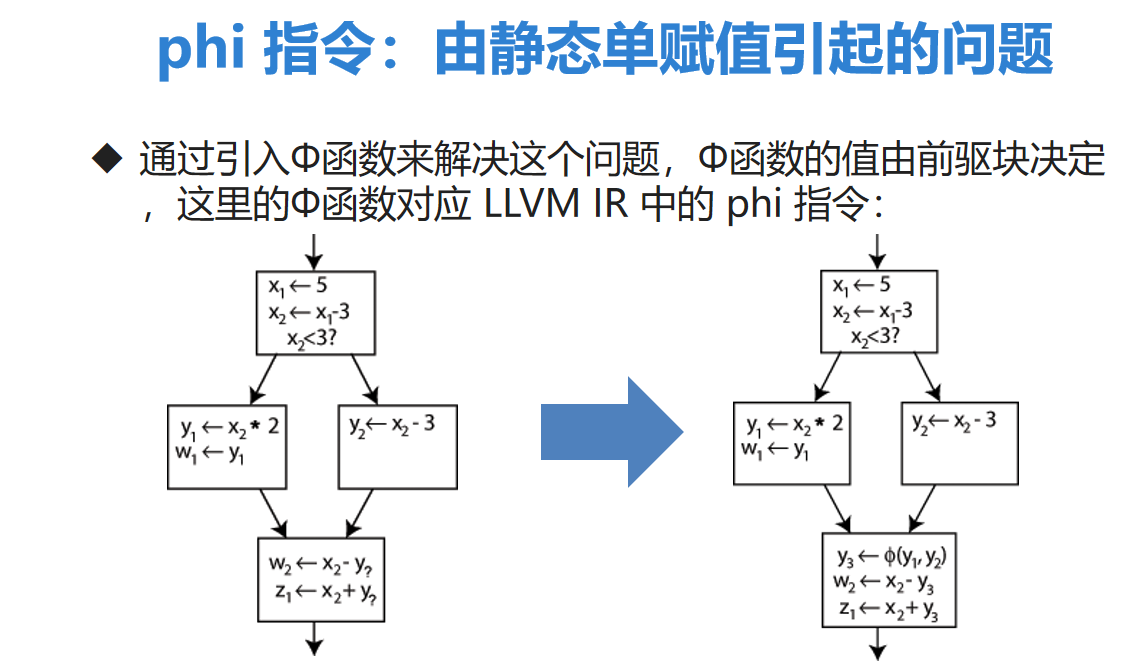
- phi 指令可以看做是为了解决 SSA 一个变量只能被赋值一次而引起的问题衍生出的指令。
- phi 指令的计算结果由 phi 指令所在的基本块的 前驱块 确定。

- 以下是一个用 phi 指令实现for循环的实例:
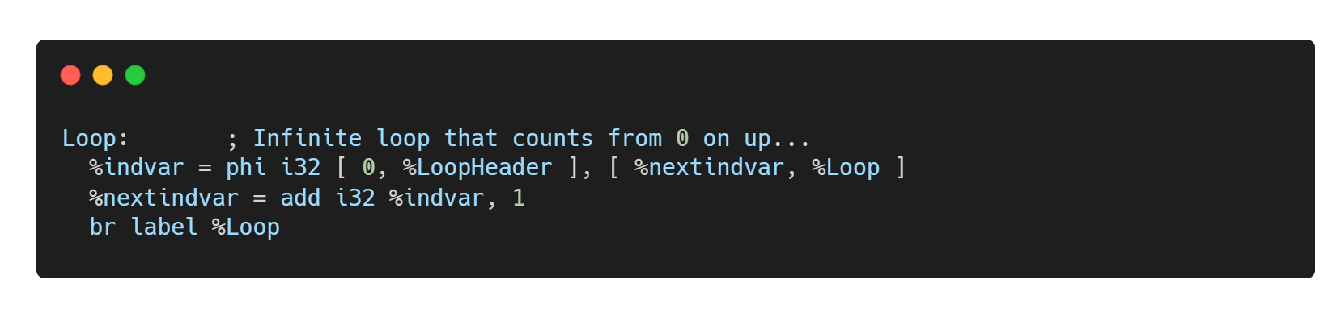
0,%LoopHeader 代表程序的前趋块是从外部进入for循环的话,phi的运算结果就是0
如果基本块的前趋块是loop,那么代表还在循环中,那么运算结果就是上一个循环中的nextindvar这个变量
后面通过add指令对 %indvar 加一
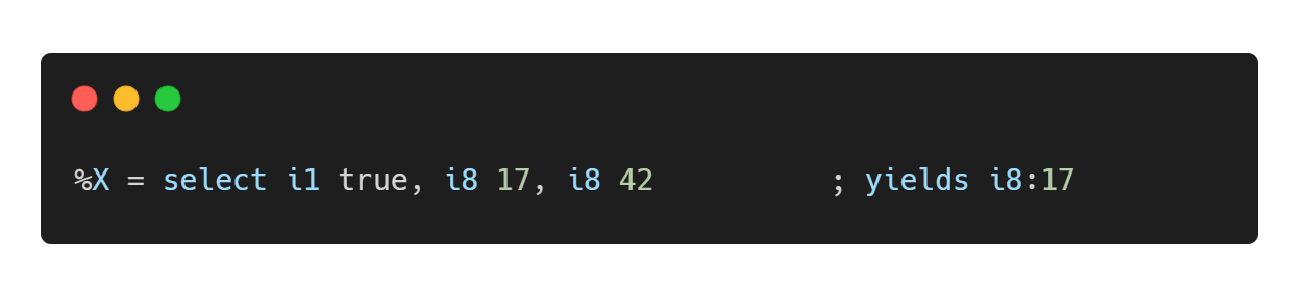
select 指令
- select 指令类似于 C/C++ 中的三元运算符”… ? … : …”

call指令
- call 指令用来调用某个函数,对应 C/C++ 中的函数调用,与x86汇编中的 call 指令类似。


C++ 基础及 LLVM Pass 常用 API
C++ 基础就 继承 多态 封装 还有 STL模板类 等.这里不详细介绍了
LLVM Pass框架中的三个核心类
- 在 LLVM Pass 框架中,三个最核心的类为 Function, BasicBlock, Instruction,分别对应 LLVM IR 中的函数、基本块和指令。
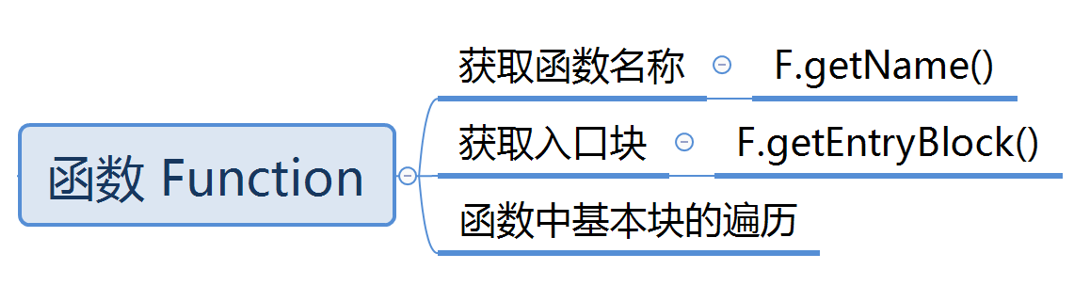
Function
-
与 Function 有关的操作主要是获取函数的一些属性,比如名称等等,以及对函数中基本块的遍历:
-
在 LLVM 中可以通过 foreach 循环对函数 Function 中的每个基本块 BasocBlock 进行遍历:

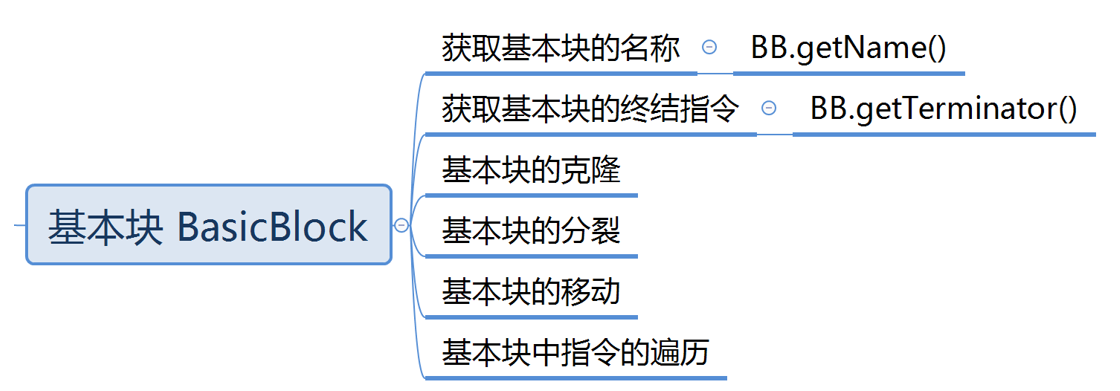
BasicBlock
- 与 BasicBlcok 有关的操作主要是基本块的克隆、分裂、移动等,以及对基本块中指令的遍历:

Instruction
- 指令可以有很多种,亦即 Instruction 类可以拥有多个子类,如:BinaryOpterator, AllocaInst, BranchInst 等。
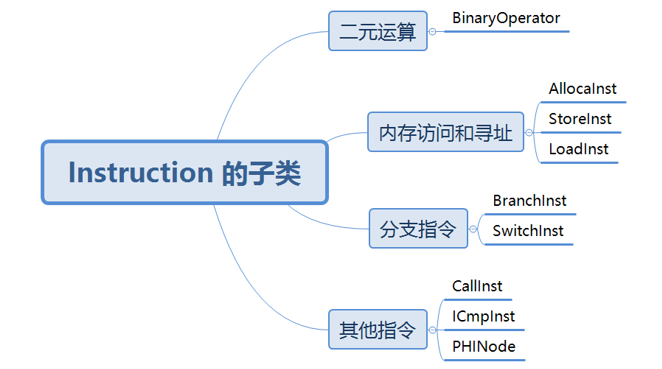
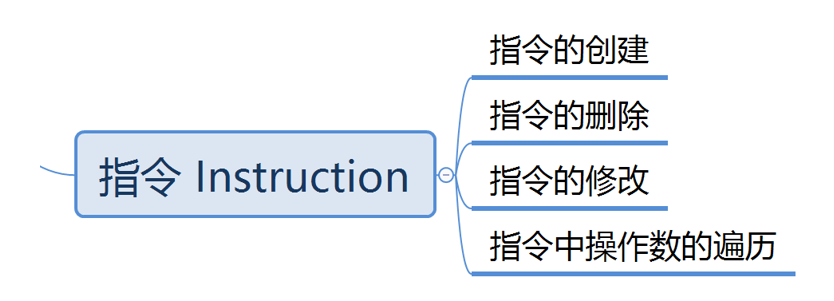
- 与 Instruction 有关的操作主要是指令的创建、删除、修改以及指令中操作数的遍历:
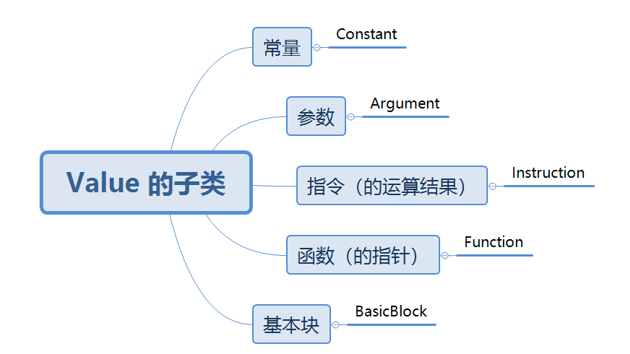
- 在 LLVM 中可以通过 for 循环对指令 Instruction 中的每个操作数 Value* 进行遍历。

- 所有可以被当做指令操作数的类型都是 Value 的子类,Value 有以下五种类型的子类。
LLVM 部分官方文档介绍

LLVM(实战篇)
基本块分割
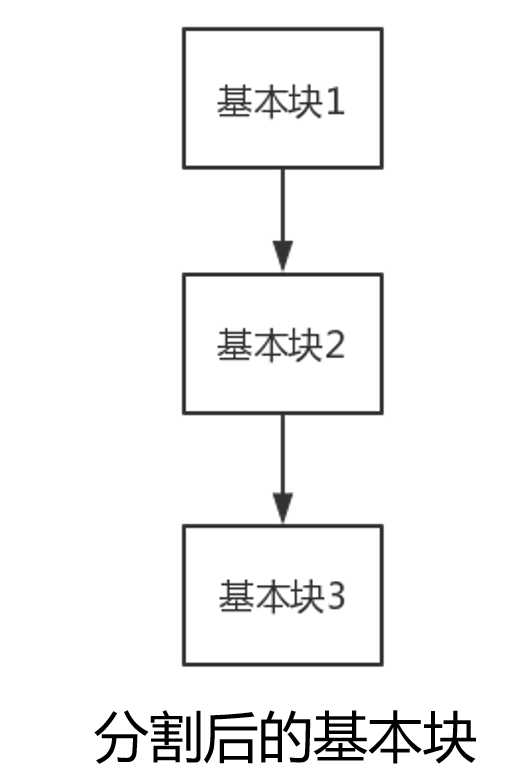
怎么实现?
- 遍历每个函数中的每个基本块,对每个基本块进行分割即可。
但是注意,有 PHI 指令的基本块我们选择跳过
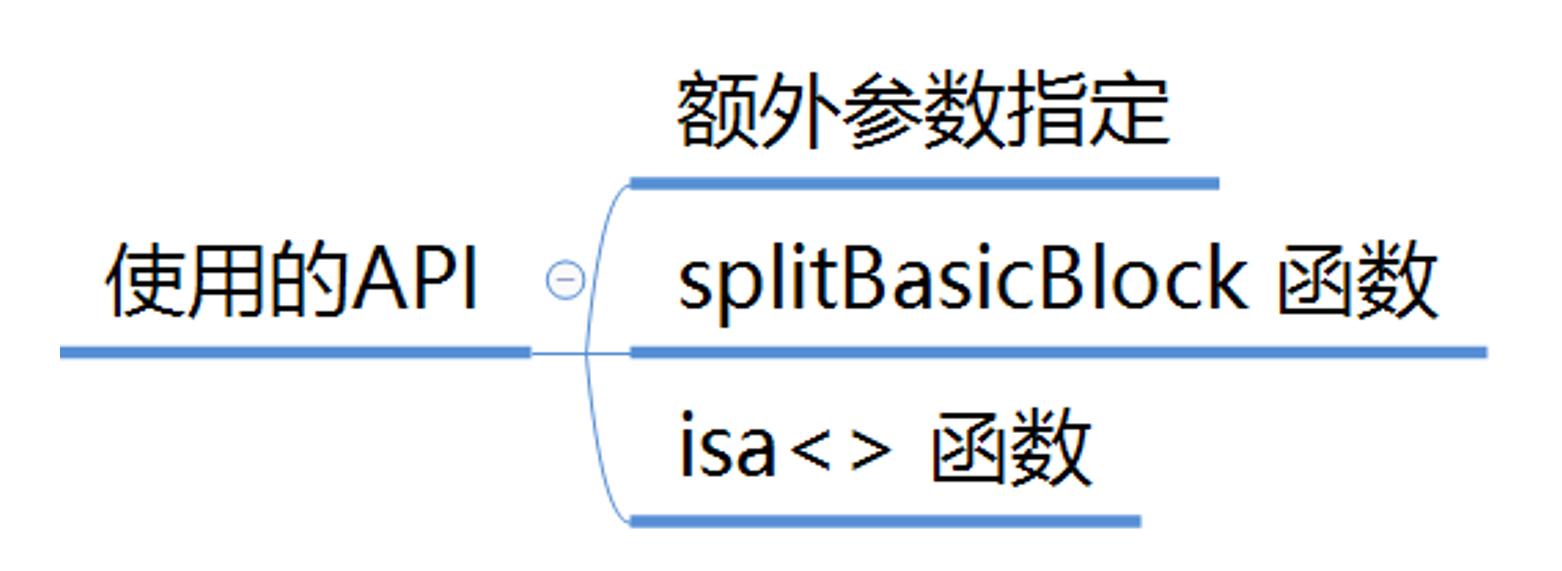
使用到的API
基本块分割主要用到了以下几个API
额外参数指定
- 在 LLVM 中,可以通过 cl::opt 模板类获取指令中的参数,这里的 opt 是选项 option 的缩写,不是优化器的意思:


splitBasicBlock函数
- splitBasicBlock 函数是 BasicBlock 类的一个成员函数。在BasicBlock.h 头文件里可以看到这个函数的两种用法:

一般都用第二个用法,第一个要迭代器。 - arg1 :就是在指令I处一分为二。也就是在指令I前的指令都会放在基本块一处,指令I及之后的指令都会放在基本块二处。然后在指令块1处建立一个绝对跳转,跳转到基本块二处。
- arg2 :指定分裂出来的基本块二的名称
- arg3 :Before如果为true,那么就会把第二个基本块移到第一个基本块的前面
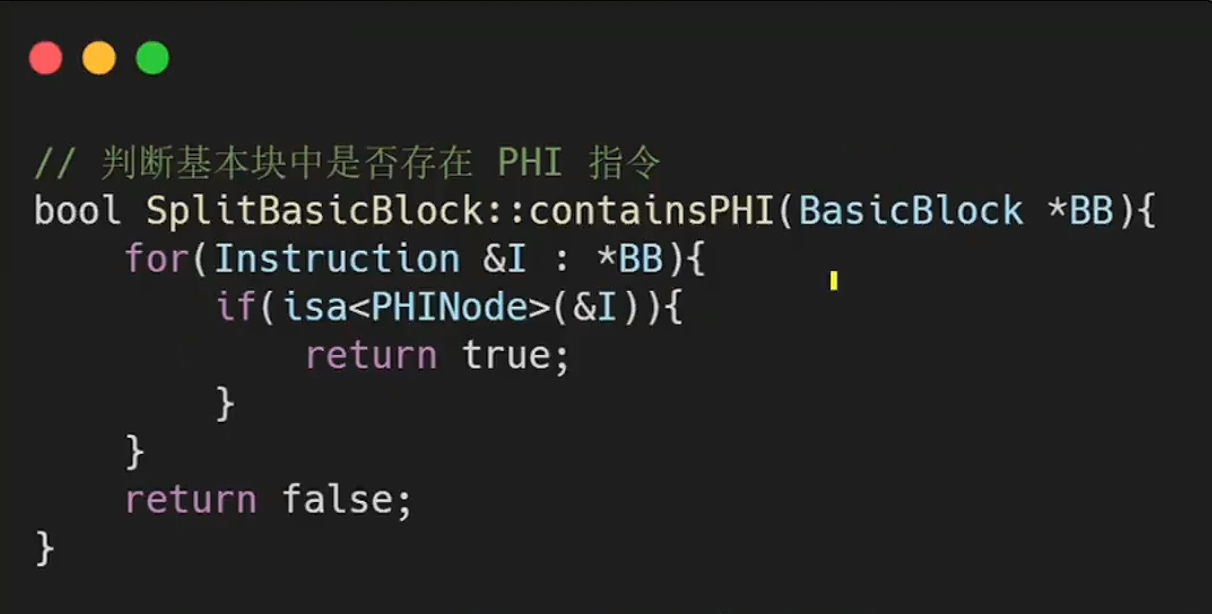
isa<>函数
- isa<> 是一个模板函数,用于判断一个指针指向的数据的类型是不是给定的类型,类似于 Java 中的 instanceof。
基本块分割
// SplitBasicBlock.cpp
#include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/IR/Instructions.h"
#include "llvm/Support/raw_ostream.h"
#include <vector>
#include <llvm/Support/CommandLine.h>
using namespace llvm;
using namespace std;
static cl::opt<int> splitNum("split_num", cl::init(2), cl::desc("Split<split_num> time(s) each BB"));
namespace{ //自定义命名空间
class SplitBasicBlock :public FunctionPass{ //继承FunctionPass类
public :
static char ID;
SplitBasicBlock():FunctionPass(ID){} //构造函数
bool runOnFunction(Function &F);
void split(BasicBlock *BB);
bool containPHI(BasicBlock *BB);
};
}
bool SplitBasicBlock::runOnFunction(Function &F){
//todo
vector<BasicBlock*> origBB;
for(BasicBlock& BB: F){
origBB.push_back(&BB);
}for(BasicBlock *BB : origBB){
if(!containPHI(BB))
split(BB);
}
}
bool SplitBasicBlock::containPHI(BasicBlock *BB){
for(Instruction &I: *BB){
if(isa<PHINode>(&I)){
return true;
}
}
}
void SplitBasicBlock::split(BasicBlock *BB){
int splitsize=(BB->size()+splitNum-1)/splitNum; //向上取整
BasicBlock *curBB=BB;
for(int i=0;i<splitNum;i++){
int cnt=0;
for(Instruction &I:*curBB){
if(cnt++==splitsize){
curBB=curBB->splitBasicBlock(&I);
break;
}
}
}
}
FunctionPass *createSplitBasicPass(){
return new SplitBasicBlock();
}
char SplitBasicBlock::ID=0;
static RegisterPass<SplitBasicBlock>X("split","split one basic block into mut"); //向LLVM注册我们的pass 其中X()中的第一个参数是指定LLVM Pass的参数 ,这样再使用opt加载这个so文件的时候,用这个参数来指定用哪个Pass来优化,第二个参数就是对Pass的描述。
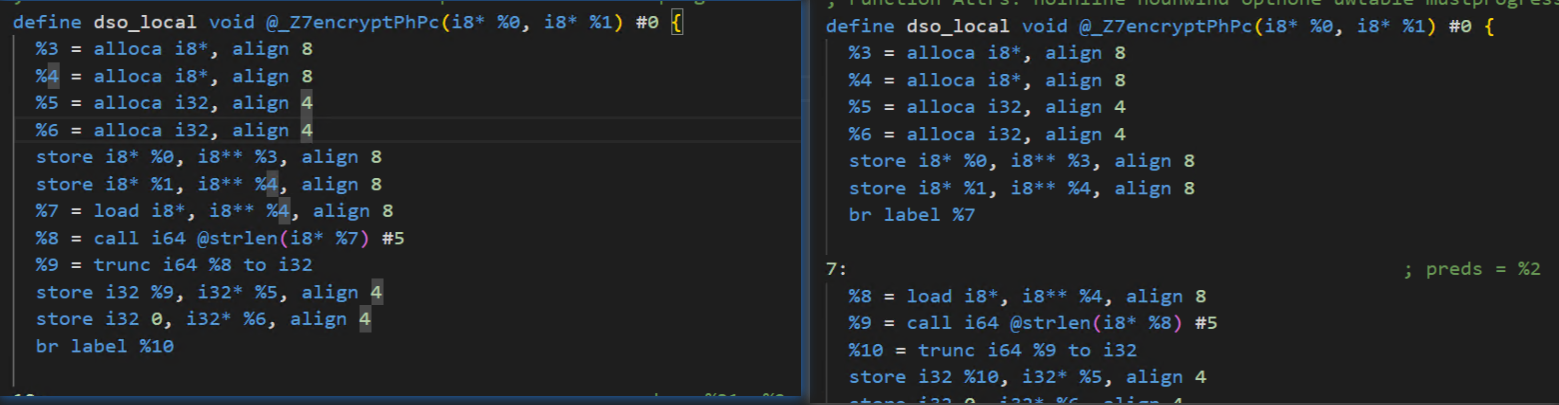
对比两个ll文件,确实能发现分割了字符串。但是经过编译优化后,最后的可执行文件使用IDA打开后发现cfg图其实还是一样的。
代码混淆基本原理
术语介绍
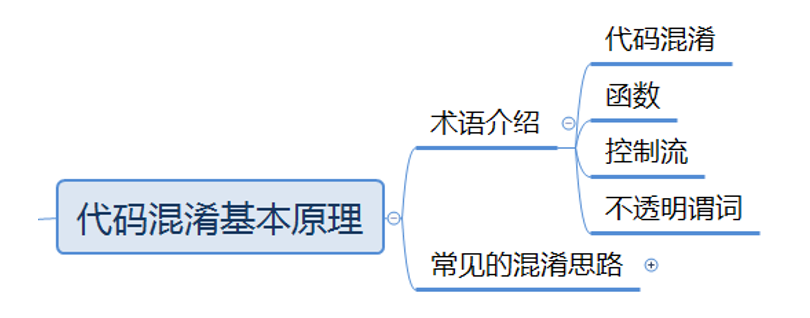
代码混淆
- 代码混淆是将计算机程序的代码,转换成一种功能上等价,但是难以阅读和理解的形式的行为。
函数
- 函数是代码混淆的基本单位,一个函数由若干个基本块组成,有且仅有一个入口块,可能有多个出口块。
- 一个函数可以用一个控制流图(Control Flow Graph, CFG)表示。
基本块
- 基本块由一组线性指令组成,每一个基本块都有一个入口点(第一条执行的指令)和一个出口点(最后一条执行的指令,亦即终结指令)。
- 终结指令要么跳转到另一个基本块(br, switch),要么从函数返回(ret)。
控制流
- 控制流代表了一个程序在执行过程中可能遍历到的所有路径。
- 通常情况下,程序的控制流很清晰地反映了程序的逻辑,但经过混淆的控制流会使得人们难以分辨正常逻辑。
不透明谓词
- 不透明谓词指的是其值为混淆者明确知晓,而反混淆者却难以推断的变量。
- 例如混淆者在程序中使用一个恒为0的全局变量,反混淆者难以推断这个变量恒为0。
控制流混淆
- 控制流混淆指的是混淆程序正常的控制流,使其在功能保持不变的情况下不能清晰地反映原程序的正常逻辑。
- 本课程中要学习的控制流混淆有:控制流平坦化、虚假控制流、随机控制流。
计算混淆
- 计算混淆指的是混淆程序的计算流程,或计算流程中使用的数据,使分析者难以分辨某一段代码所执行的具体计算。

经典代码混淆工具 OLLVM 体验
OLLVM 介绍
Obfuscator-LLVM(简称OLLVM)是2010年6月由瑞士西部应用科学大学(HEIG-VD)的信息安全小组发
起的一个项目。 这个项目的目的是提供一个 LLVM 编译套件的开源分支,能够通过代码混淆和防篡改提
供更高的软件安全性。OLLVM 提供了三种经典的代码混淆:
- 控制流平坦化 Control Flow Flattening
- 虚假控制流 Bogus Control Flow
- 指令替代 Instruction Subsititution
OLLVM 在国内移动安全的使用非常广泛,虽然 OLLVM 已于2017年停止更新,并且到目前为止,三种
代码混淆方式均已有成熟的反混淆手段 。但是 OLLVM 的各种变体仍然在被开发和使用(如王者荣耀的
某个so文件),OLLVM 至今仍有很大的学习价值。
OLLVM 初体验
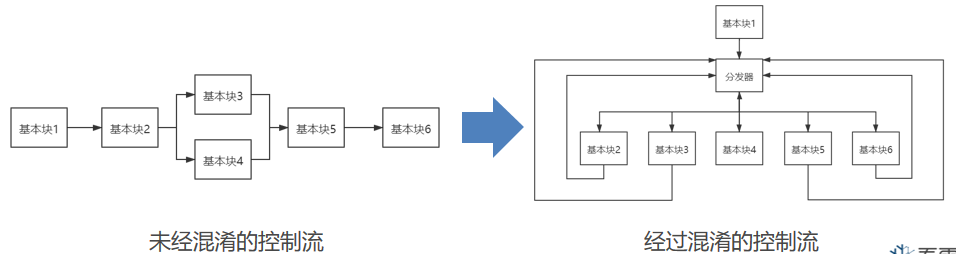
控制流平坦化(Control Flow Flattening)
可用选项:
- -mllvm -fla : 激活控制流平坦化
- -mllvm -split : 激活基本块分割
- -mllvm -split_num=3 : 指定基本块分割的数目,这里一个基本款会被分割成3个基本块后再进行控制流平坦化混淆
示例
clang -mllvm -fla -mllvm -split -mllvm -split_num=3 TestProgram.cpp -o TestProgram_fla
若在编译时出现 stddef.h 和 stdarg.h 头文件不存在的错误,可以使用 locate stddef.h 和
locate stdarg.h 指令找到这两个头文件的位置,然后复制到 /usr/include
或 /usr/local/include 目录下。
虚假控制流(Bogus Control Flow)
- -mllvm -bcf : 激活虚假控制流
- -mllvm -bcf_loop=3 : 混淆次数,这里一个函数会被混淆3次,默认为 1
- -mllvm -bcf_prob=40 : 每个基本块被混淆的概率,这里每个基本块被混淆的概率为40%,默认为30
示例
clang -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -bcf_prob=40 TestProgram.cpp -o TestProgram_bcf
指令替换(Instruction Substitution)
- -mllvm -sub : 激活指令替代
- -mllvm -sub_loop=3 : 混淆次数,这里一个函数会被混淆3次,默认为 1
示例
clang -mllvm -sub -mllvm -sub_loop=3 TestProgram.cpp -o TestProgram_sub
OLLVM 原理分析
控制流平坦化(Control Flow Flattening)
- 入口块:进入函数第一个执行的基本块。
- 主分发块与子分发块:负责跳转到下一个要执行的原基本块。
- 原基本块:混淆之前的基本块,真正完成程序工作的基本块。
- 返回块:返回到主分发块。
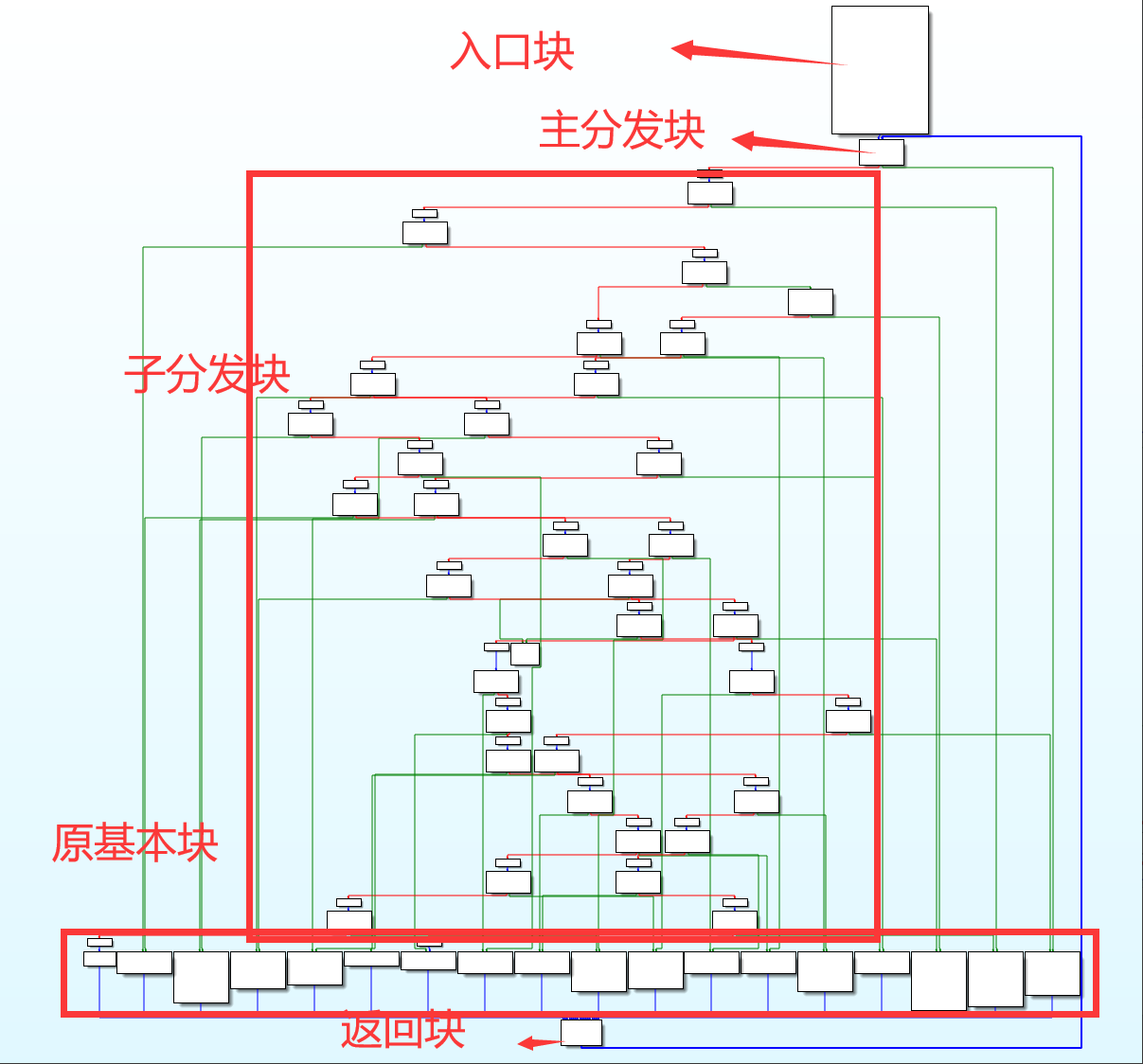
代码实现与分析
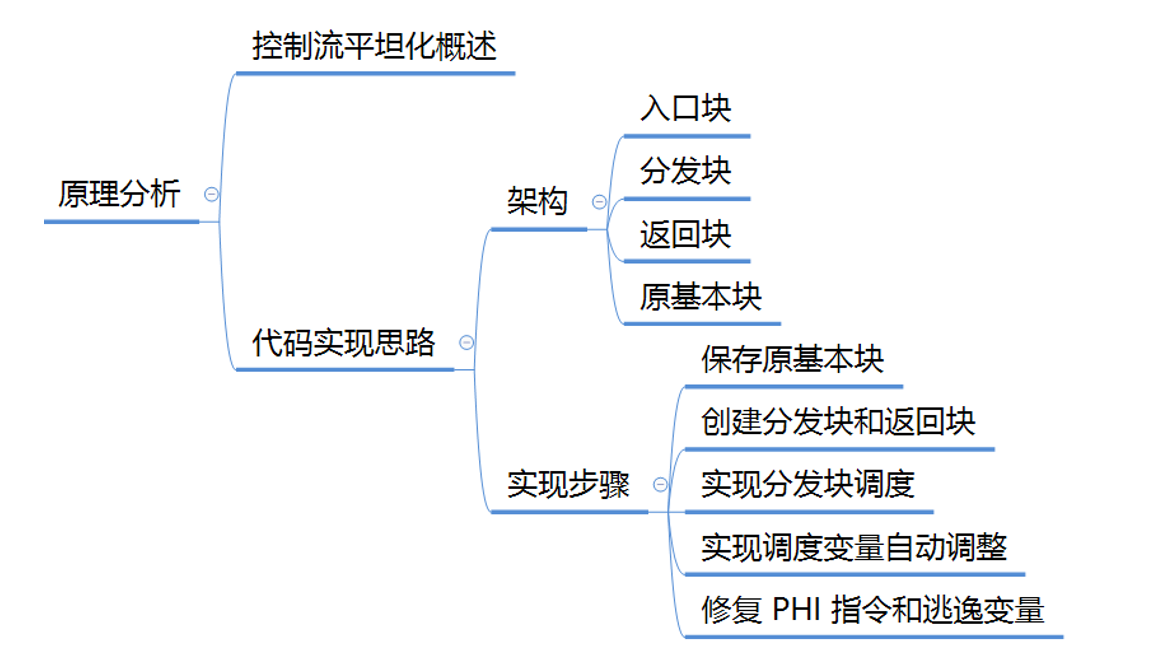
第一步:保存原基本块
- 将除入口块以外的以外的基本块保存到 vector 容器中,方便后续处理。
- 如果入口块的终结指令是条件分支指令,则将该指令单独分离出来作为一个基本块,加入到 vector 容器的最前面。

第二步:创建分发块和返回块
- 除了原基本块之外,我们还要继续创建一个分发块来调度基本块的执行顺序。并建立入口块到分发块的绝对跳转。
- 再创建一个返回块,原基本块执行完后都需要跳转到这个返回块,返回块会直接跳转到分发块。
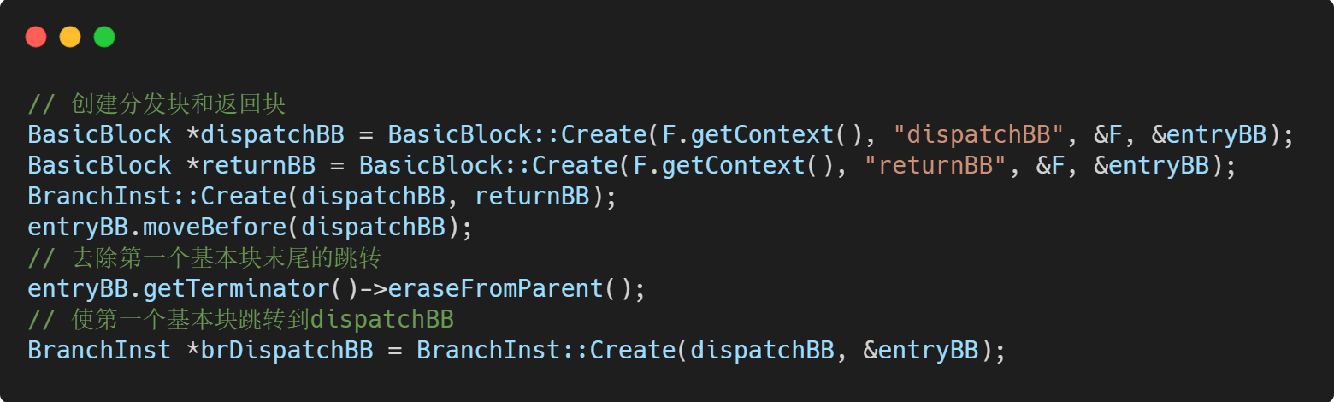
其中,这个BasicBlock::Create函数中的 参数说明
- 第一个参数是一个LLVMContext
- 第二个参数是指创建的基本块的名称
- 第三个参数是函数指针(也就是你要在哪个函数里创建基本块)
- 第四个参数指向了一个基本块,代表我们创建的基本块会被移动到这个基本块的前面(是物理上的移动)
但是这样会破坏之前的物理顺序与其逻辑关系相对应的规律,所以我们要通过moveBefore方法来把我们的入口块移动到最前面,然后删除入口块的最后一条指令,然后跳转到分发块。
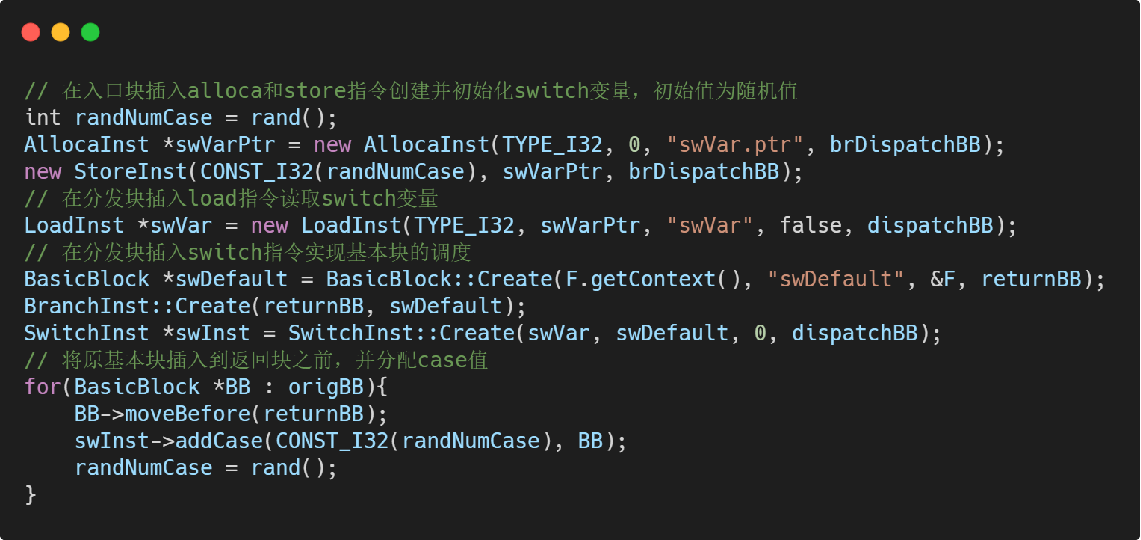
第三步:实现分发块调度
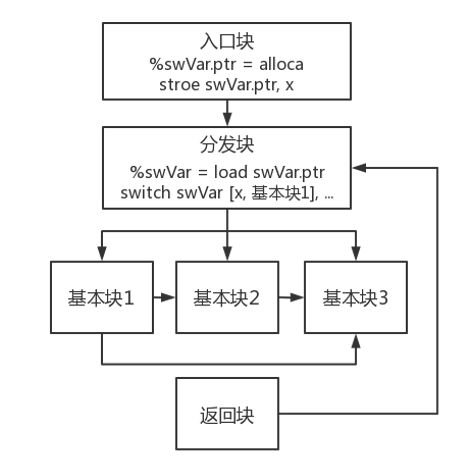
- 在入口块中创建并初始化 switch 变量,在调度块中插入switch 指令实现分发功能。
- 将原基本块移动到返回块之前,并分配随机的 case 值,并将其添加到 switch 指令的分支中。
第四步:实现调度变量自动调整
- 在每个原基本块最后添加修改 switch 变量值的指令,以便返回分发块之后,能够正确执行到下一个基本块。
- 删除原基本块末尾的跳转,使其结束执行后跳转到返回块。
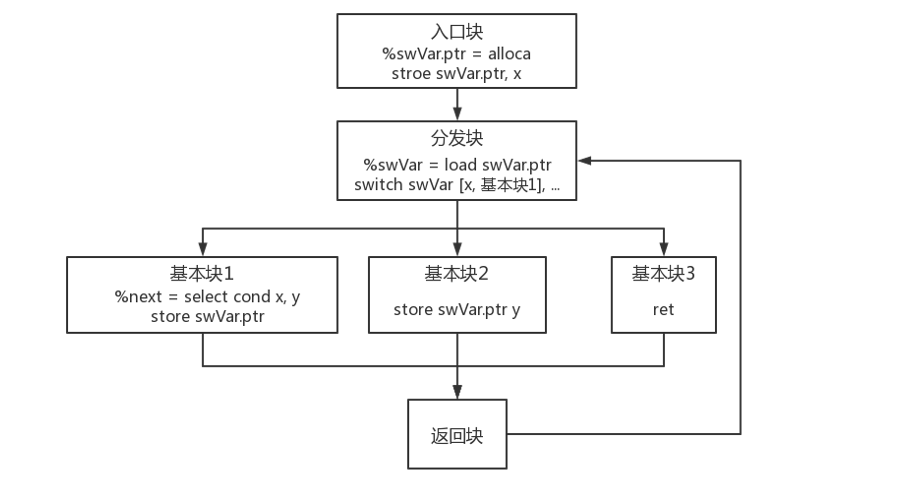
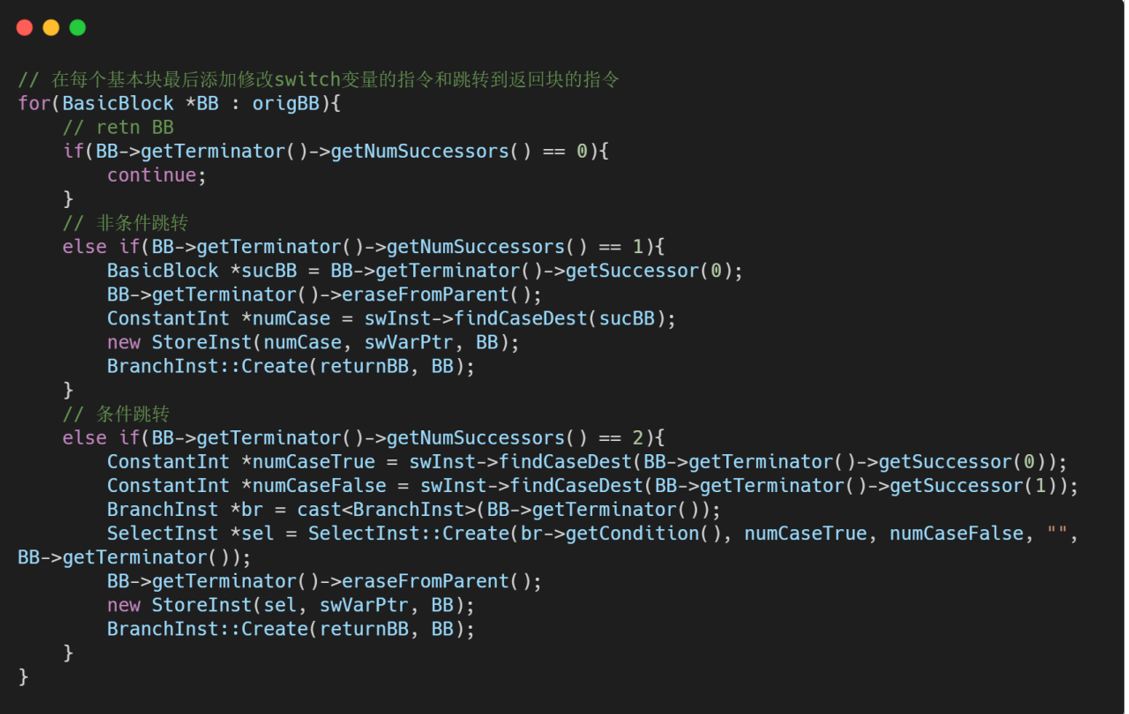
第五步:修复 PHI 指令和逃逸变量
- PHI 指令的值由前驱块决定,平坦化后所有原基本块的前驱块都变成了分发块,因此 PHI 指令发生了损坏。
- 逃逸变量指在一个基本块中定义,并且在另一个基本块被引用的变量。在原程序中某些基本块可能引用之前某个基本块中的变量,平坦化后原基本块之间不存在确定的前后关系了(由分发块决定),因此某些变量的引用可能会损坏。
- 修复的方法是,将 PHI 指令和逃逸变量都转化为内存存取指令。
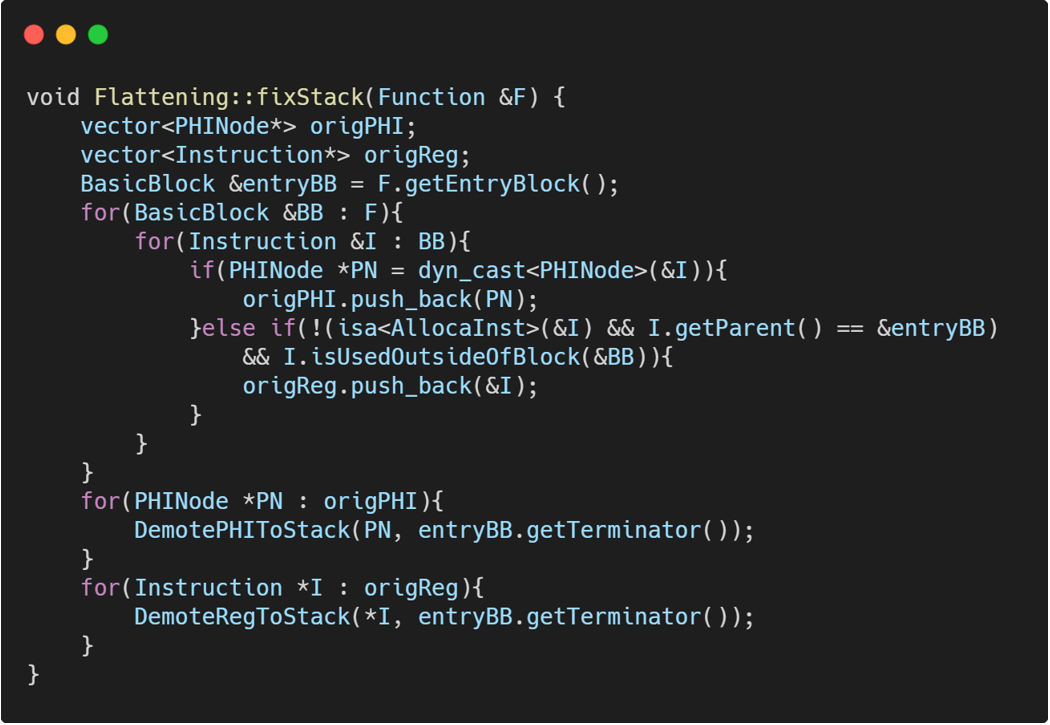
全部代码
Flattening.cpp
#include "llvm/IR/Function.h"
#include "llvm/Pass.h"
#include "llvm/IR/LegacyPassManager.h"
#include "llvm/Transforms/IPO/PassManagerBuilder.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/IR/Instructions.h"
#include "llvm/Transforms/Utils.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Transforms/Utils/Local.h"
#include "SplitBasicBlock.h"
#include "Utils.h"
#include <vector>
#include <cstdlib>
#include <ctime>
using namespace llvm;
using std::vector;
namespace{
class Flattening :public FunctionPass{
public :
static char ID;
Flattening():FunctionPass(ID){
srand(time(0));
}
void flatten(Function &F);
bool runOnFunction(Function &F);
};
}
bool Flattening::runOnFunction(Function &F){
INIT_CONTEXT(F);
flatten(F);
return true;
}
void Flattening::flatten(Function &F){
//第一步,保存除了入口块的基本块
vector<BasicBlock*> origBB;
for(BasicBlock& BB:F){
origBB.push_back(&BB);
}
origBB.erase(origBB.begin());
BasicBlock &entryBlock=F.getEntryBlock();
if(BranchInst *br=dyn_cast<BranchInst>(entryBlock.getTerminator())){
if(br->isConditional()){//判断是不是条件跳转
origBB.insert(origBB.begin(),entryBlock.splitBasicBlock(br));
}
}
//第二步,创建分发块和返回块
BasicBlock *dispatchBB=BasicBlock::Create(*CONTEXT,"dispatchBB",&F,&entryBlock);
BasicBlock *retBB=BasicBlock::Create(*CONTEXT,"retBB",&F,&entryBlock);
entryBlock.moveBefore(dispatchBB);
entryBlock.getTerminator()->eraseFromParent();
BranchInst::Create(dispatchBB,&entryBlock);
BranchInst::Create(dispatchBB,retBB);
//第三部,实现分发块的调度功能
int randNumcase=rand();
AllocaInst * swVarPtr =new AllocaInst(TYPE_I32,0,"swVar.ptr",entryBlock.getTerminator());
new StoreInst(CONST_I32(randNumcase),swVarPtr,entryBlock.getTerminator());
LoadInst *swVar=new LoadInst(TYPE_I32,swVarPtr,"swVAR",dispatchBB);
BasicBlock *defaultBB = BasicBlock::Create(*CONTEXT,"defaultBB",&F,retBB);
BranchInst::Create(retBB,defaultBB); //基本块肯定要有一条中间指令,所以这里随便添加一条跳转指令
SwitchInst *swInst=SwitchInst::Create(swVar,defaultBB,0,dispatchBB);//插入到分发块的后面
//为每个基本块分配随机的case值
for(BasicBlock *BB:origBB){
BB->moveBefore(retBB);
swInst->addCase(CONST_I32(randNumcase),BB);
randNumcase=rand();
}
//第四步 实现调度变量自动调整
for(BasicBlock *BB:origBB){
if(BB->getTerminator()->getNumSuccessors()==0){//如果这个基本块的最后一条指令是返回指令(没有后继快)
continue;
} else if(BB->getTerminator()->getNumSuccessors()==1){//如果这个基本块还有一个后继块(即为绝对跳转)
ConstantInt *numcase = swInst->findCaseDest(BB->getTerminator()->getSuccessor(0));
new StoreInst(numcase,swVarPtr,BB->getTerminator());
BB->getTerminator()->eraseFromParent();
BranchInst::Create(retBB,BB);
}else if(BB->getTerminator()->getNumSuccessors()==2){ //有两个后继块
ConstantInt *numcase1 = swInst->findCaseDest(BB->getTerminator()->getSuccessor(0));
ConstantInt *numcase2 = swInst->findCaseDest(BB->getTerminator()->getSuccessor(1));
BranchInst *br1=cast<BranchInst>(BB->getTerminator()); //两个分支也有可能是switch指令,但是在混淆前,使用LLVM IR指令 (使用自带的 LowerSwitch的LLVM Pass),将switch替换成了branch,所以这里最后一条指令只能是branch
SelectInst *sel=SelectInst::Create(br1->getCondition(),numcase1,numcase2,"",BB->getTerminator());
new StoreInst(sel,swVarPtr,BB->getTerminator());
BB->getTerminator()->eraseFromParent(); //删除原先的终结指令
BranchInst::Create(retBB,BB);
}
}
//第五步 修复 phi指令和逃逸变量
fixStack(F);
}
char Flattening::ID=0;
static RegisterPass<Flattening>X("fla","My control flow flattening obfuscation");
Utils.cpp
#include"Utils.h"
#include<vector>
#include "llvm/IR/Instructions.h"
#include "llvm/Transforms/Utils/Local.h"
#include "llvm/Transforms/Utils/ValueMapper.h"
#include "llvm/Transforms/Utils/Cloning.h"
using std::vector;
using namespace llvm;
LLVMContext *CONTEXT=nullptr;
void llvm::fixStack(Function &F){
vector<PHINode*> origPHI;
vector<Instruction*> origReg;
BasicBlock &entryBB=F.getEntryBlock();
for(BasicBlock &BB:F){
for (Instruction &I:BB)
{
if(PHINode *PN=dyn_cast<PHINode>(&I)){
origPHI.push_back(PN);
}else if(!(isa<AllocaInst>(&I)&& I.getParent()==&entryBB)&& I.isUsedOutsideOfBlock(&BB)){//判断是不是逃逸变量(除了通过Alloc,并且定义在入口块的,都要处理)
origReg.push_back(&I);
}
}
}
for(PHINode *PN:origPHI){
DemotePHIToStack(PN,entryBB.getTerminator());
}
for(Instruction *I:origReg){
DemoteRegToStack(*I,entryBB.getTerminator());
}
}
头文件啥的就不放了
虚假控制流 (Bogus Control Flow)
- 虚假控制流指,通过向正常控制流中插入若干不可达基本块(永远不会被执行的基本块)和由不透明谓词造成的虚假跳转,以产生大量垃圾代码干扰攻击者分析的混淆。
原理分析
- 虚假控制流是以基本块为单位进行混淆的,每个基本块要经过分裂、克隆、构建虚假跳转等操作。
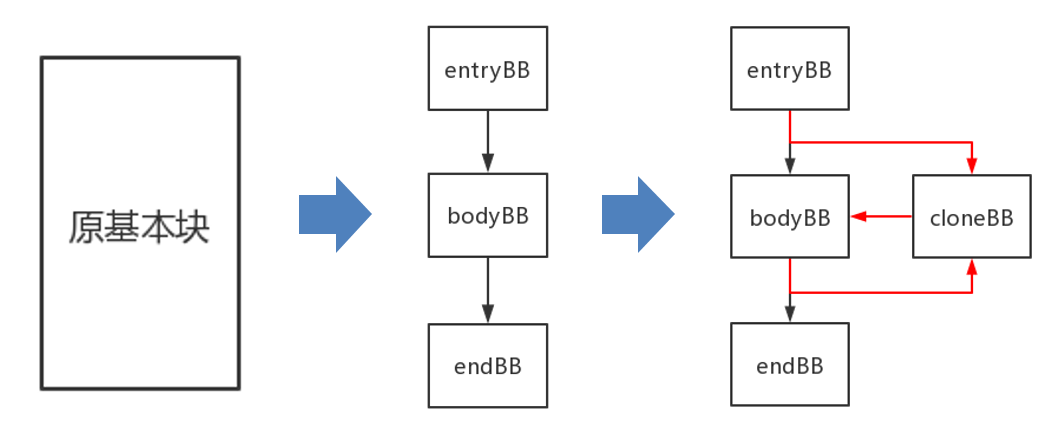
第一步 基本块拆分
- 通过 getFirstNonPHI 函数获取第一个不是 PHINode 的指令,以该指令为界限进行分割,得到 entryBB 和 bodyBB。(授课人说根据经验,PHI指令往往都会堆积在基本块的最前部,即在第一个不是PHINode指令的前面)
- 以 bodyBB 的终结指令为界限进行分割,最终得到头部、中部和尾部三个基本块,也就是 entryBB, bodyBB 和 endBB。

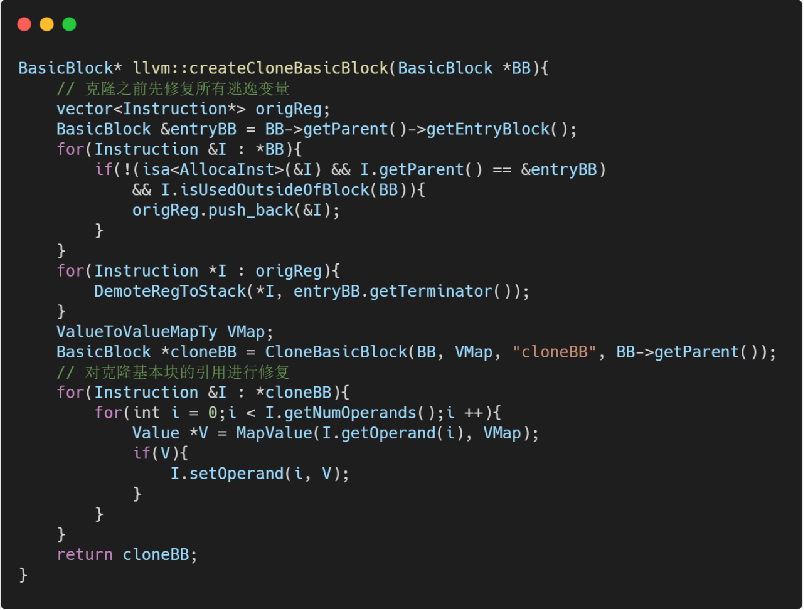
第二步 基本块克隆(克隆bodyBB)
- LLVM 自带 CloneBasicBlock 函数,但该函数为不完全克隆,还需要做一些补充处理。
- 我们把基本块的克隆操作写到 createCloneBasicBlock 函数中:

在克隆的基本块中,仍然引用了原基本块中的 %a 变量,该引用是非法的,故需要将 %a 映射为 %a.clone:
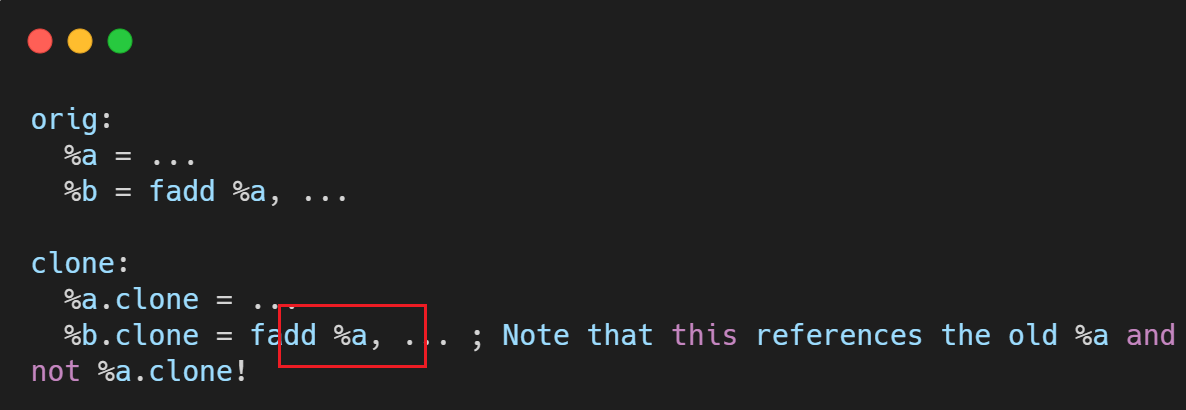
- 根据 VMap 对克隆基本块中的变量进行修复:
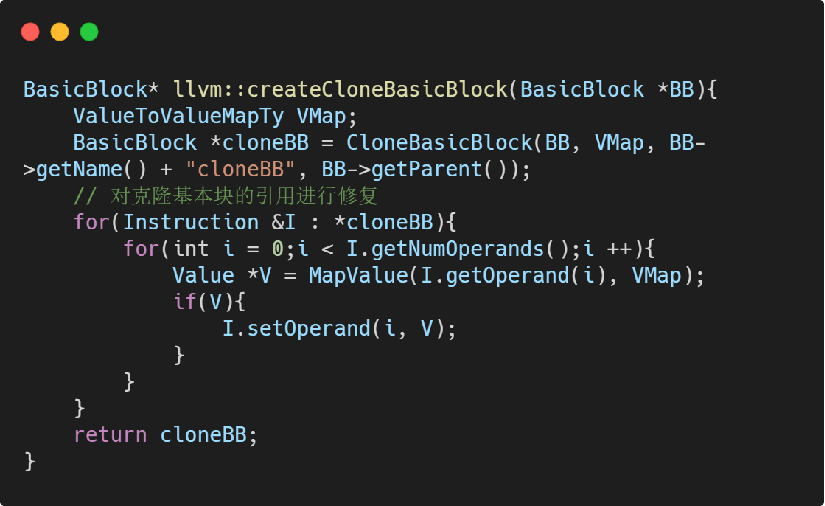
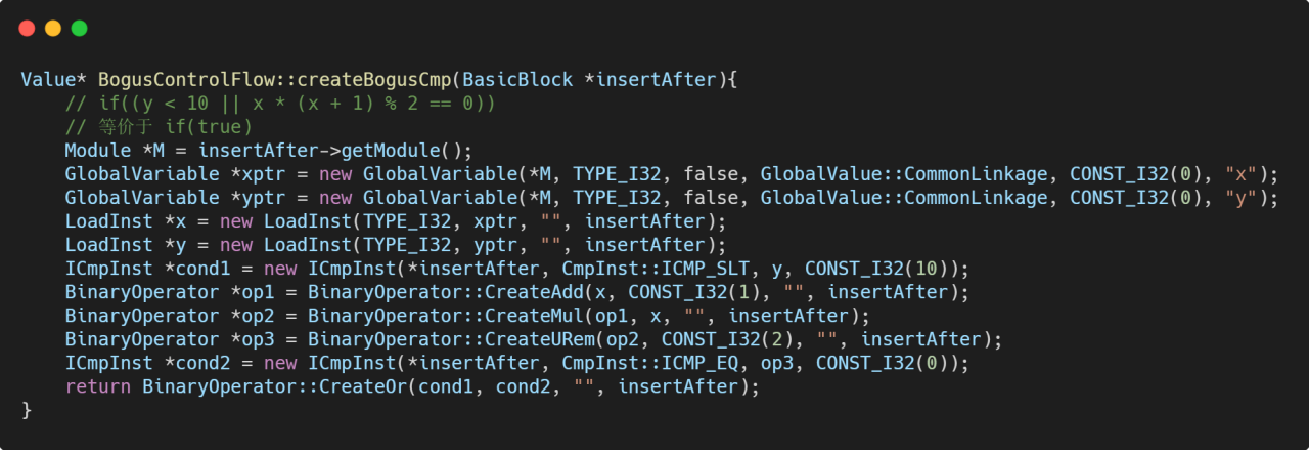
第三步 构造虚假跳转

- 该比较指令等价于 if(y < 10 || x * (x + 1) % 2 == 0):
OLLVM其实还对克隆块进行了变异的处理,往里面添加很多随机的指令
代码实现
#include "llvm/IR/Function.h"
#include "llvm/Pass.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Transforms/Utils/ValueMapper.h"
#include "llvm/Transforms/Utils/Cloning.h"
#include "llvm/IR/Module.h"
#include "llvm/IR/Instructions.h"
#include "SplitBasicBlock.h"
#include "Utils.h"
#include <vector>
#include <cstdlib>
#include <ctime>
using std::vector;
using namespace llvm;
static cl::opt<int> obfuTimes("bcf_loop",cl::init(1),cl::desc("Obfucase a function <bcf_loop> time()."));
namespace{
class BogusControlFlow : public FunctionPass{
public:
static char ID;
BogusControlFlow():FunctionPass(ID){
srand(time(NULL));
}
bool runOnFunction(Function &F);
void bogus(BasicBlock *BB);
Value * createBogusCmp(BasicBlock *insertAfter);
};
}
bool BogusControlFlow::runOnFunction(Function &F){
INIT_CONTEXT(F);
FunctionPass *pass =createSplitBasicBlockPass();
pass->runOnFunction(F);
for(int i=0;i<obfuTimes;i++){
vector<BasicBlock*> origBB;
for(BasicBlock& BB:F){
origBB.push_back(&BB);
}
for(BasicBlock *BB:origBB){
bogus(BB);
}
}
return true;
}
Value *BogusControlFlow::createBogusCmp(BasicBlock * insertAfter){
Module *M=insertAfter->getModule();
GlobalVariable *xptr= new GlobalVariable(*M,TYPE_I32,false,GlobalValue::CommonLinkage,CONST_I32(0),"x"); // False -> 不是常量 设置 x 初始值为 0;
GlobalVariable *yptr= new GlobalVariable(*M,TYPE_I32,false,GlobalValue::CommonLinkage,CONST_I32(0),"y");
LoadInst *x=new LoadInst(TYPE_I32,xptr,"",insertAfter); //全局变量不能直接使用,用load来读取
LoadInst *y=new LoadInst(TYPE_I32,yptr,"",insertAfter);
ICmpInst *cmp1=new ICmpInst(*insertAfter,CmpInst::ICMP_SLT,y,CONST_I32(10));
BinaryOperator *opt1=BinaryOperator::CreateAdd(x,CONST_I32(1),"",insertAfter);
BinaryOperator *opt2=BinaryOperator::CreateMul(x,opt1,"",insertAfter);
BinaryOperator *opt3=BinaryOperator::CreateSRem(opt2,CONST_I32(2),"",insertAfter);
ICmpInst *cmp2=new ICmpInst(*insertAfter,CmpInst::ICMP_EQ,opt3,CONST_I32(0));
return BinaryOperator::CreateOr(cmp1,cmp2,"",insertAfter);
}
void BogusControlFlow::bogus(BasicBlock *entryBB){
BasicBlock *bodyBB=entryBB->splitBasicBlock(entryBB->getFirstNonPHI(),"BodyBB");
BasicBlock *endBB=bodyBB->splitBasicBlock(bodyBB->getTerminator(),"endBB");
//第二步,对中间的基本块 BodyBB 进行克隆,得到cloneBB
BasicBlock *cloneBB=createCloneBasicBlock(bodyBB);
//第三部 构建虚假跳转
entryBB->getTerminator()->eraseFromParent();
bodyBB->getTerminator()->eraseFromParent();
cloneBB->getTerminator()->eraseFromParent();
Value *cond1 =createBogusCmp(entryBB);//创建恒为真的比较式
Value *cond2 =createBogusCmp(bodyBB);
BranchInst::Create(bodyBB,cloneBB,cond1,entryBB);
BranchInst::Create(endBB,cloneBB,cond2,bodyBB);
BranchInst::Create(bodyBB,cloneBB);
}
char BogusControlFlow::ID=0;
static RegisterPass<BogusControlFlow> X("bcf","My control bogus control flattening obfuscation"); //向LLVM注册我们的pass 其中X()中的第一个参数是指定LLVM Pass的参数 ,这样再使用opt加载这个so文件的时候,用这个参数来指定用哪个Pass来优化,第二个参数就是对Pass的描述。
指令替代
原理分析
- 指令替代指将正常的二元运算指令(如加法、减法、异或等等),替换为等效而更复杂的指令序列,以达到混淆计算过程的目的。
- 例如将 a+b 替换为 a - (-b) ,将 a ^ b 替换为 (~a & b) | (a & ~b) 等等
- 仅支持整数运算的替换,因为替换浮点指令会造成舍入的错误和误差。
总体思路
扫描所有指令,对目标指令(加法、减法、与或非、异或)进行替换:

加法替换

减法替换
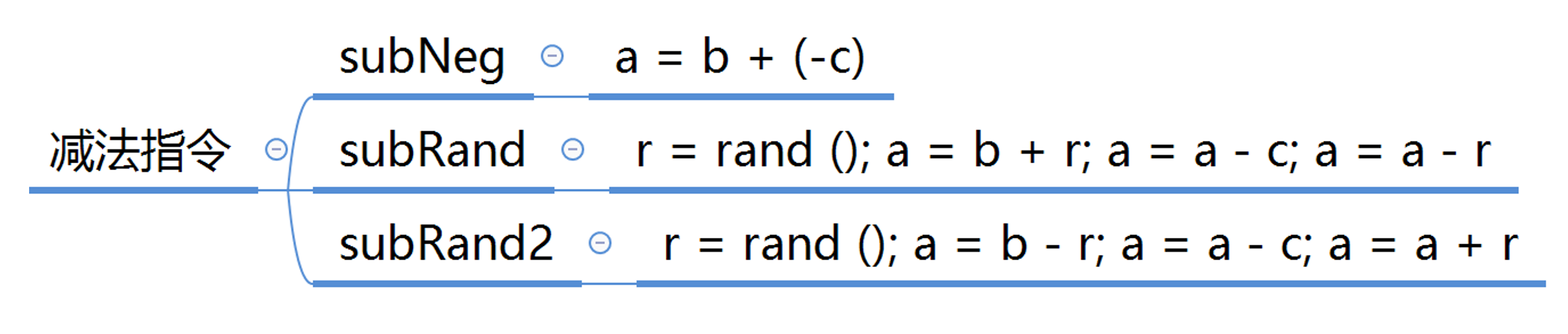
与替换

或替换

异或替换
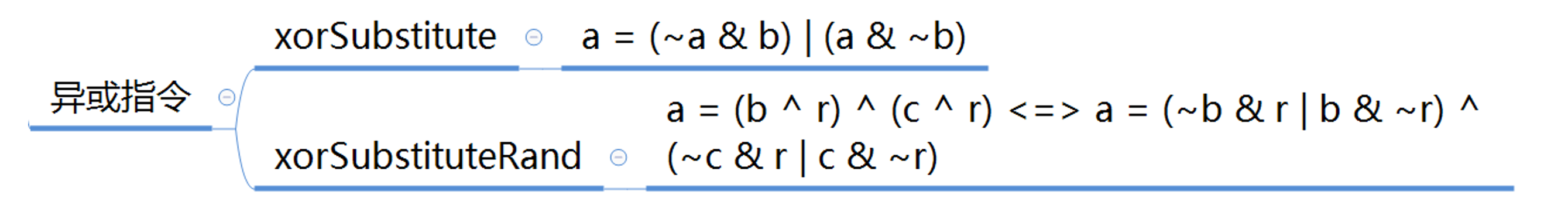
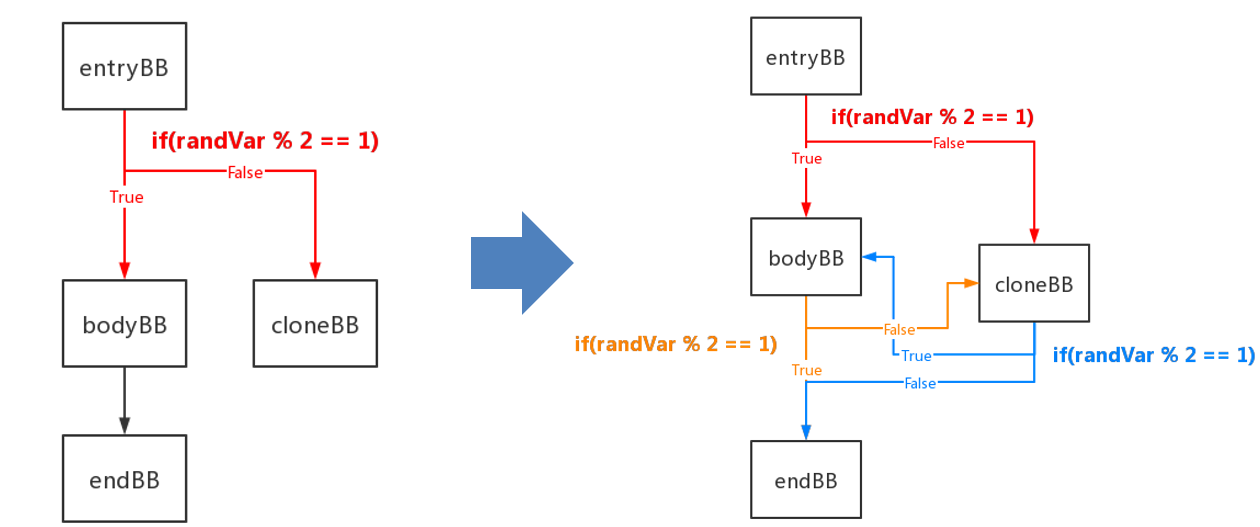
随机控制流
- 随机控制流是虚假控制流的一种变体,随机控制流通过克隆基本块,以及添加随机跳转(随机跳转到两个功能相同的基本块中的一个)来混淆控制流。
- 与虚假控制流不同,随机控制流中不存在不可达基本块和不透明谓词,因此用于去除虚假控制流的手段(消除不透明谓词、符号执行获得不可达基本块后去除)失效。
- 随机控制流的控制流图与虚假控制流类似,都呈长条形。
混淆效果
- 随机的跳转和冗余的不可达基本块导致了大量垃圾代码,严重干扰了攻击者的分析。
- 并且 rdrand 指令可以干扰某些符号执行引擎(如 angr)的分析。

原理分析
- 随机控制流同样是以基本块为单位进行混淆的,每个基本块要经过分裂、克隆、构造随机跳转和构造虚假随机跳转四个操作。
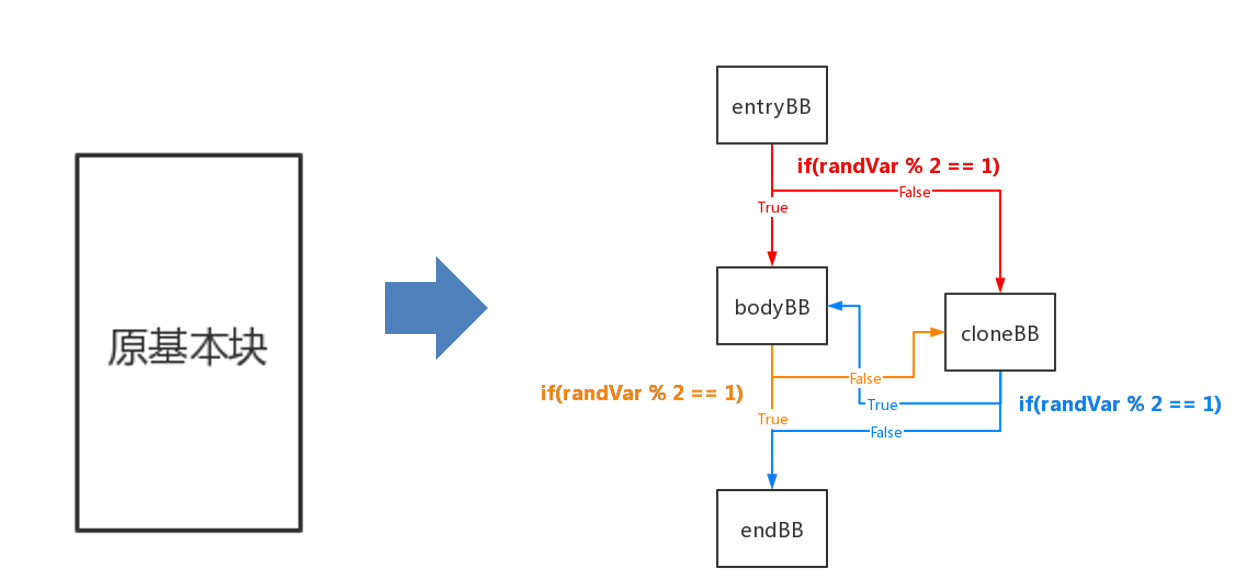
一. 基本块拆分
不多说,和虚假控制流一样,分成三个基本块。
- 通过 getFirstNonPHI 函数获取第一个不是 PHINode 的指令,以该指令为界限进行分割,得到 entryBB 和 bodyBB。
- 以 bodyBB 的终结指令为界限进行分割,最终得到头部、中部和尾部三个基本块,也就是 entryBB, bodyBB 和 endBB。

二.基本块克隆
和虚假控制流一样,但是还是有些出入,还要修复逃逸变量。
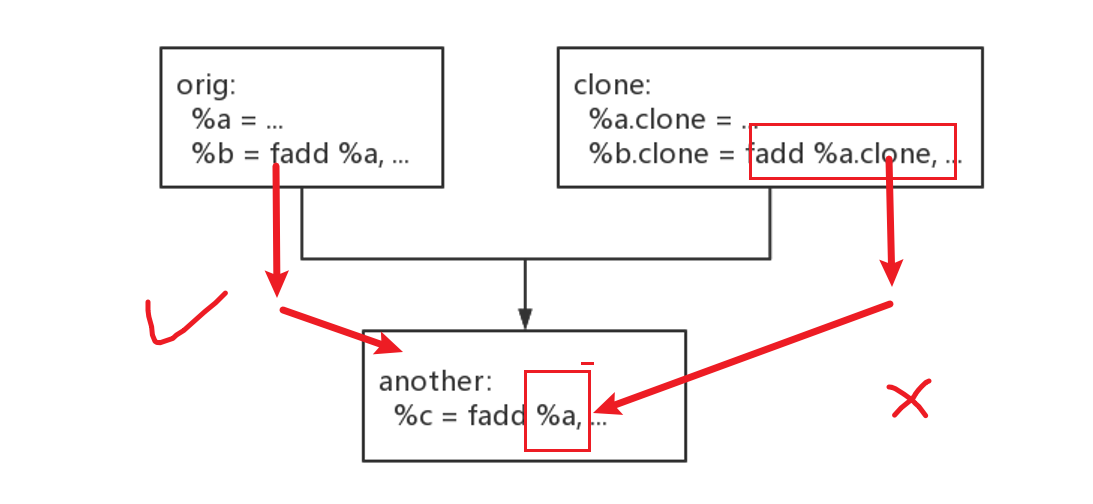
所以克隆前要先修复逃逸变量
三.构造随机跳转
- 将生成随机数的指令插入到 entryBB ,将生成的随机数命名为 randVar,并在 entryBB 后插入基于 randVar 的随机跳转指令。
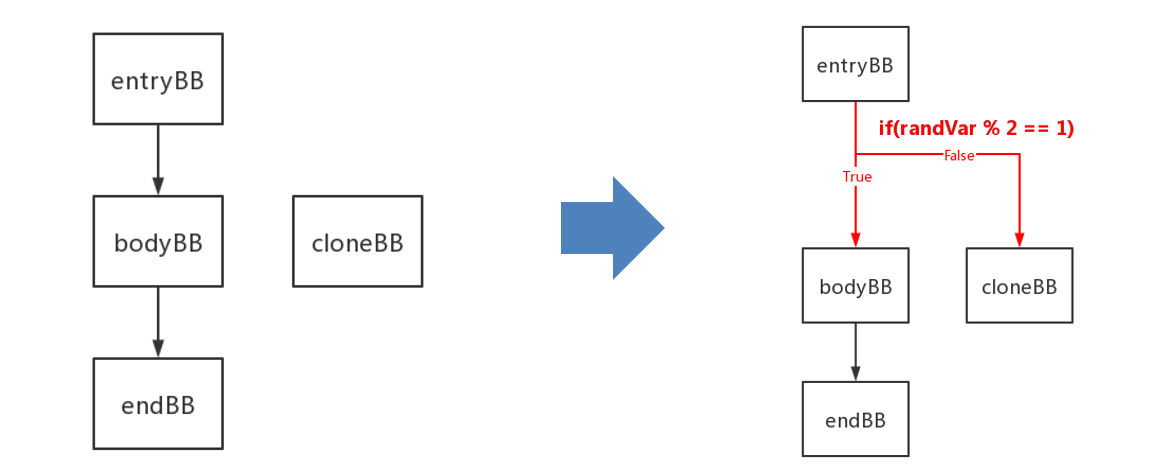
- 向 entryBB 中插入生成随机数的指令和随机跳转,使其能够随机跳转到 bodyBB 或者 bodyBB 的克隆块。
- 其中随机数指令我们可以使用 LLVM 的内置函数 rdrand:


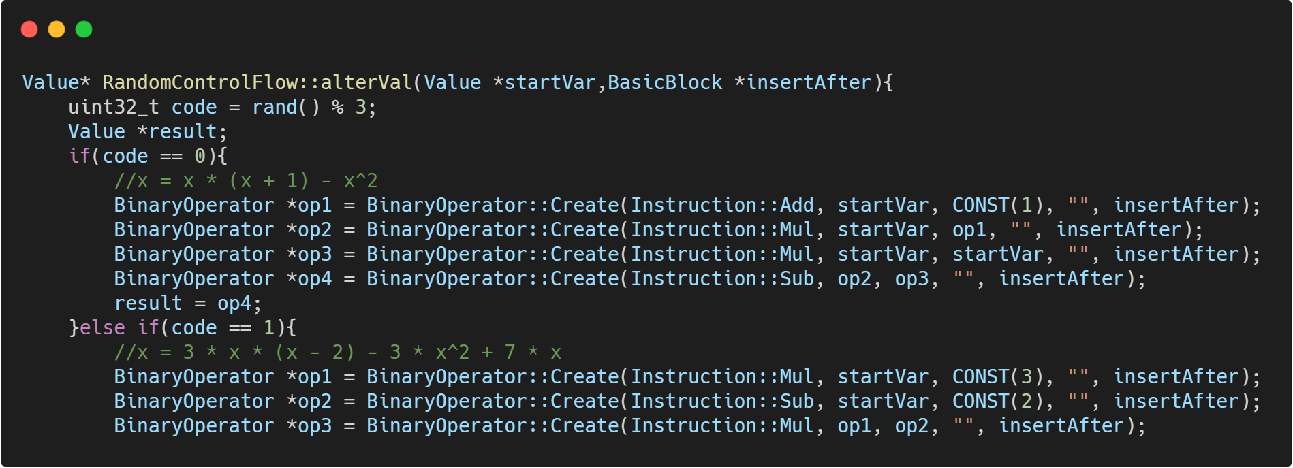
第四步 构造虚假随机跳转
- 在 bodyBB 和 cloneBB 后插入虚假随机跳转指令(实际上仍会直接跳转到 endBB):

#include "llvm/IR/Function.h"
#include "llvm/Pass.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Transforms/Utils/ValueMapper.h"
#include "llvm/Transforms/Utils/Cloning.h"
#include "llvm/IR/Module.h"
#include "llvm/IR/Instructions.h"
#include "SplitBasicBlock.h"
#include "llvm/IR/IRBuilder.h"
#include "Utils.h"
#include <vector>
#include <cstdlib>
#include <ctime>
#include "llvm/IR/Intrinsics.h"
#include "llvm/IR/IntrinsicsX86.h"
#include "RandomControlFlow.h"
using namespace llvm;
using std::vector;
static cl::opt<int>obfuTimes("rcf_loop",cl::init(1),cl::desc("Obfuscate a function <bef_loop>time(s)."));
namespace{
class RandomControlFlow: public FunctionPass{
public:
static char ID;
RandomControlFlow():FunctionPass(ID){
srand(time(NULL));
}
Value* alterVal(Value *origVar,BasicBlock *insertAfter);
bool runOnFunction(Function &F);
void insertRandomBranch(Value *randVar,BasicBlock *ifTrue,BasicBlock *ifFalse,BasicBlock *insertAfter);
bool randcf(BasicBlock *entryBB);
};
}
bool RandomControlFlow::runOnFunction(Function &F){
INIT_CONTEXT(F);
FunctionPass *pass=createSplitBasicBlockPass();
pass->runOnFunction(F);
for(int i=0;i<obfuTimes;i++){
vector<BasicBlock*>origBB;
for(BasicBlock &BB:F){
origBB.push_back(&BB);
}
for(BasicBlock *BB:origBB){
randcf(BB);
}
}
return true;
}
//以基本块为单位进行随机控制流混淆
bool RandomControlFlow::randcf(BasicBlock *entryBB){
//第一步 将基本块拆分
BasicBlock *bodyBB=entryBB->splitBasicBlock(entryBB->getFirstNonPHI(),"entryBB");
BasicBlock *endBB=bodyBB->splitBasicBlock(bodyBB->getTerminator(),"endBB");
//第二步,对基本块进行克隆,并且修复逃逸变量
BasicBlock *cloneBB=createCloneBasicBlock(bodyBB);
//第三步,构建随机跳转
*entryBB->getTerminator()->eraseFromParent();
Function *randfunc=Intrinsic::getDeclaration(entryBB->getModule(),llvm::Intrinsic::x86_rdrand_32); //获取32位随机数
CallInst *callinst=CallInst::Create(randfunc->getFunctionType(),randfunc,"",entryBB);
Value *randVar=ExtractValueInst::Create(callinst,0,"",entryBB);//将生成的随机数插入到 entryBB的尾部
insertRandomBranch(randVar,bodyBB,cloneBB,entryBB);
//第四步 bodyBB和cloneBB添加随机跳转
bodyBB->getTerminator()->eraseFromParent();
cloneBB->getTerminator()->eraseFromParent();
insertRandomBranch(randVar,bodyBB,endBB,cloneBB);
insertRandomBranch(randVar,endBB,cloneBB,bodyBB);
}
//插入随机跳转,随机数为randvar
//如果 randvar %2==1 就跳转到ifTrue ,否则跳转到ifFalse;
void RandomControlFlow::insertRandomBranch(Value *randVar,BasicBlock *ifTrue,BasicBlock *ifFalse,BasicBlock *insertAfter){
Value *alteredRandVar=alterVal(randVar,insertAfter);
Value *randMod2=BinaryOperator::CreateURem(alteredRandVar,CONST_I32(2),"",insertAfter);
CmpInst *cmp1=new ICmpInst(*insertAfter,ICmpInst::ICMP_EQ,randMod2,CONST_I32(0),"");
BranchInst *branch=BranchInst::Create(ifTrue,ifFalse,cmp1,insertAfter);
}
//对变量进行恒等变换
Value* RandomControlFlow::alterVal(Value *startVar,BasicBlock *insertAfter){
uint32_t code = rand() % 3;
Value *result;
if (code == 0) {
// x = x * (x + 1) - x^2
BinaryOperator *op1 = BinaryOperator::Create(Instruction::Add, startVar,
CONST_I32(1), "", insertAfter);
BinaryOperator *op2 = BinaryOperator::Create(Instruction::Mul, startVar,
op1, "", insertAfter);
BinaryOperator *op3 = BinaryOperator::Create(Instruction::Mul, startVar,
startVar, "", insertAfter);
BinaryOperator *op4 =
BinaryOperator::Create(Instruction::Sub, op2, op3, "", insertAfter);
result = op4;
} else if (code == 1) {
// x = 3 * x * (x - 2) - 3 * x^2 + 7 * x
BinaryOperator *op1 = BinaryOperator::Create(Instruction::Mul, startVar,
CONST_I32(3), "", insertAfter);
BinaryOperator *op2 = BinaryOperator::Create(Instruction::Sub, startVar,
CONST_I32(2), "", insertAfter);
BinaryOperator *op3 =
BinaryOperator::Create(Instruction::Mul, op1, op2, "", insertAfter);
BinaryOperator *op4 = BinaryOperator::Create(Instruction::Mul, startVar,
startVar, "", insertAfter);
BinaryOperator *op5 = BinaryOperator::Create(Instruction::Mul, op4,
CONST_I32(3), "", insertAfter);
BinaryOperator *op6 = BinaryOperator::Create(Instruction::Mul, startVar,
CONST_I32(7), "", insertAfter);
BinaryOperator *op7 =
BinaryOperator::Create(Instruction::Sub, op3, op5, "", insertAfter);
BinaryOperator *op8 =
BinaryOperator::Create(Instruction::Add, op6, op7, "", insertAfter);
result = op8;
} else if (code == 2) {
// x = (x - 1) * (x + 3) - (x + 4) * (x - 3) - 9
BinaryOperator *op1 = BinaryOperator::Create(Instruction::Sub, startVar,
CONST_I32(1), "", insertAfter);
BinaryOperator *op2 = BinaryOperator::Create(Instruction::Add, startVar,
CONST_I32(3), "", insertAfter);
BinaryOperator *op3 = BinaryOperator::Create(Instruction::Add, startVar,
CONST_I32(4), "", insertAfter);
BinaryOperator *op4 = BinaryOperator::Create(Instruction::Sub, startVar,
CONST_I32(3), "", insertAfter);
BinaryOperator *op5 =
BinaryOperator::Create(Instruction::Mul, op1, op2, "", insertAfter);
BinaryOperator *op6 =
BinaryOperator::Create(Instruction::Mul, op3, op4, "", insertAfter);
BinaryOperator *op7 =
BinaryOperator::Create(Instruction::Sub, op5, op6, "", insertAfter);
BinaryOperator *op8 = BinaryOperator::Create(Instruction::Sub, op7,
CONST_I32(9), "", insertAfter);
result = op8;
}
return result;
}
FunctionPass *llvm::createRandomControlFlow() {
return new RandomControlFlow();
}
char RandomControlFlow::ID = 0;
static RegisterPass<RandomControlFlow> X("rcf","My Random control flow obfuscation");
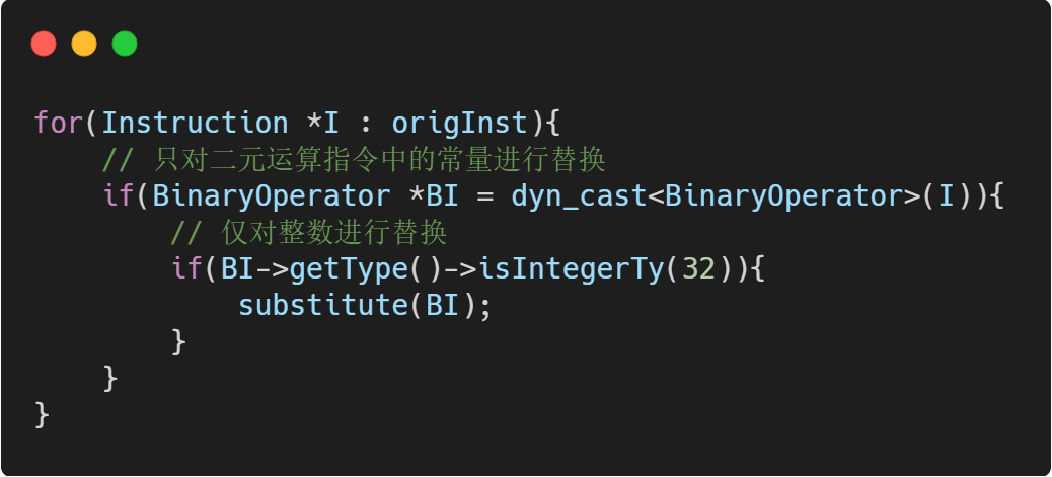
常量替代
-
常量替代指将二元运算指令(如加法、减法、异或等等)中使用的常数,替换为等效而更复杂的表达式,以达到混淆计算过程或某些特殊常量的目的。
-
例如将 TEA 加密中使用的常量 0x9e3779b 替换为 1216716715+1885832146-643678438。
-
同指令替代,目前仅支持整数常量的替换,因为替换浮点数会造成舍入的错误和误差。且仅支持32位整数的替换,大家课后可以尝试拓展到任意位数整数的替换。
-
常量替代可进一步拓展为常量数组的替代和字符串替代。
-
常量数组替代可以抹去 AES, DES 等加密算法中特征数组,字符串替代可以防止攻击者通过字符串定位关键代码。
总体思路
- 扫描所有指令,对目标指令(操作数类型为32位整数)进行替换:
- 线性替换:val -> ax + by + c
- 其中 val 为原常量 a, b 为随机常量 x, y 为随机全局变量 c = val - (ax + by)
- 按位运算替换:val -> (x << 5 | y >> 3) ^ c
- 其中 val 为原常量x, y 为随机全局变量 c = val ^ (x << 5 | y >> 3)
评论区