



流量分析
USB流量分析
由于USB流量分为键盘流量和鼠标流量,而键盘数据包的数据长度为八个字节,鼠标数据包的数据长度为四个字节。
键盘流量
键盘流量为8个字节,按键信息在第三位上,并且不同的大小对应不同的键位。
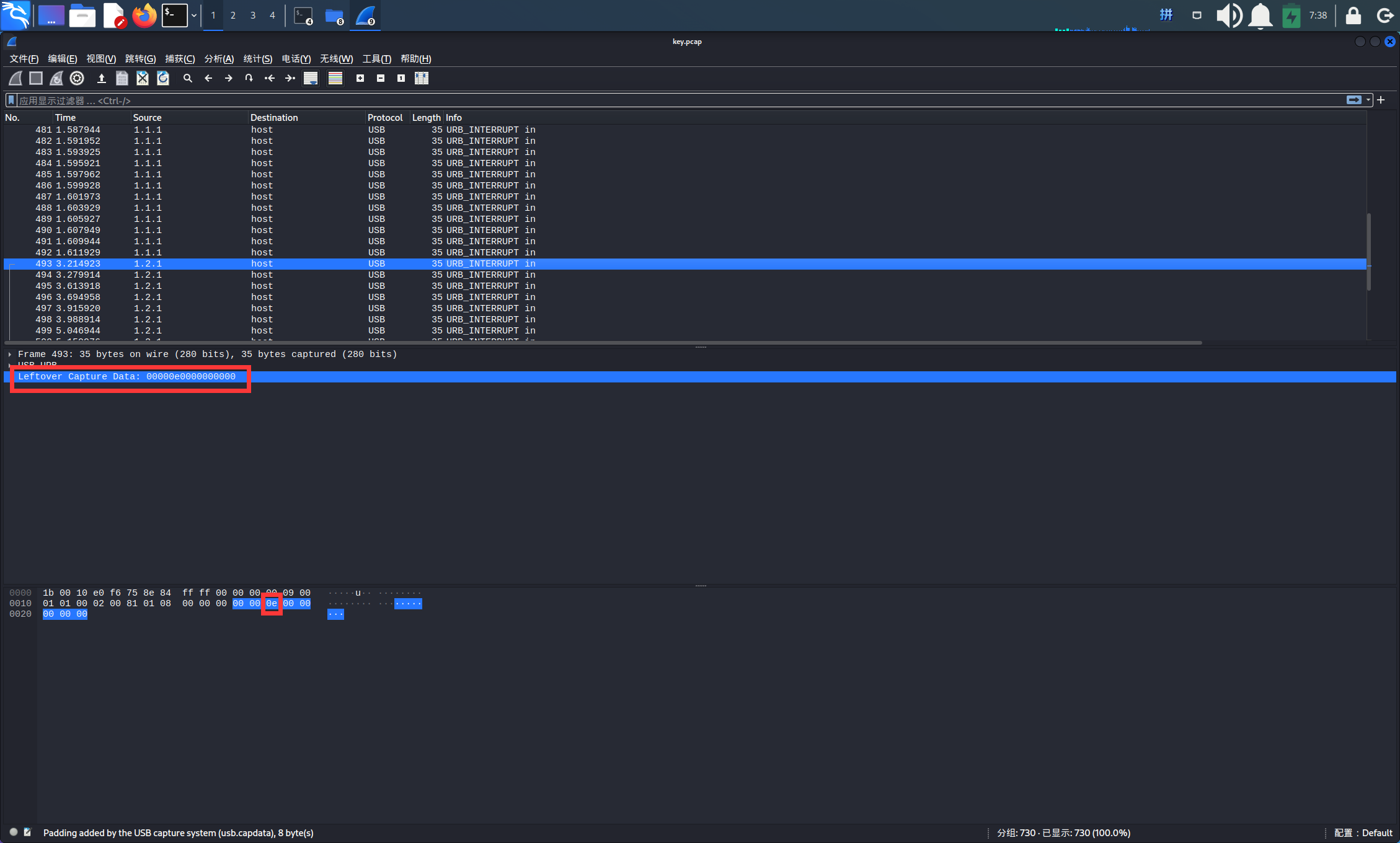 如图,0x0e根据映射表对应为字符‘K’。
如图,0x0e根据映射表对应为字符‘K’。
例题
法一,使用UsbKeyboardDataHacker.py(超链接)

法二,tshark提取
拿到数据包,先用tshark命令可以将 leftover capture data单独提取出来
tshark -r ××× -T fields -e usb.capdata > usbdata.txt
如果输出的数据中中有空行,使用此命令消除空行(否则会发生错误)
tshark -r ××× -T fields -e usb.capdata | sed '/^\s*$/d' > usbdata.txt
然后得到usbdata.txt
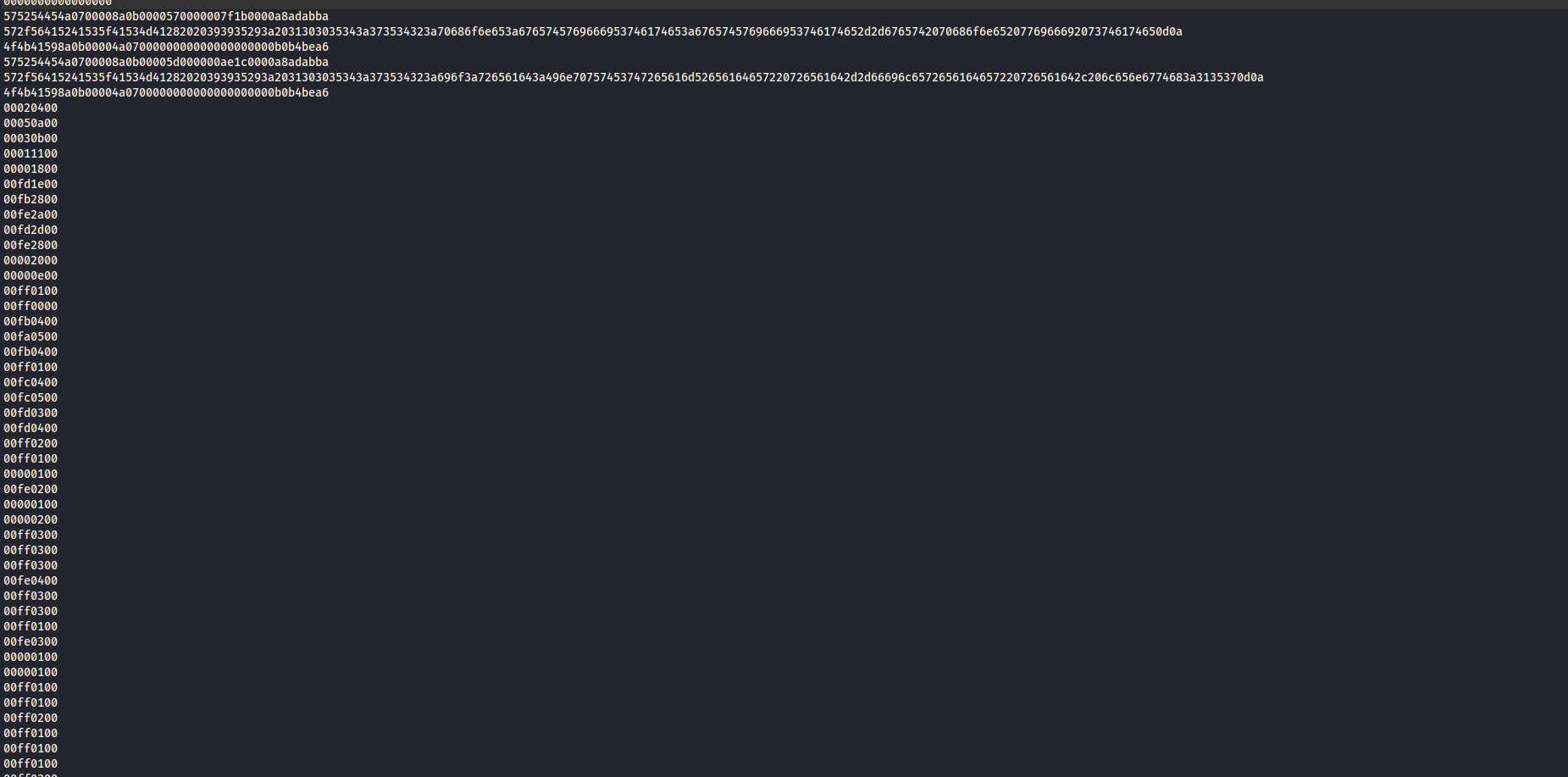
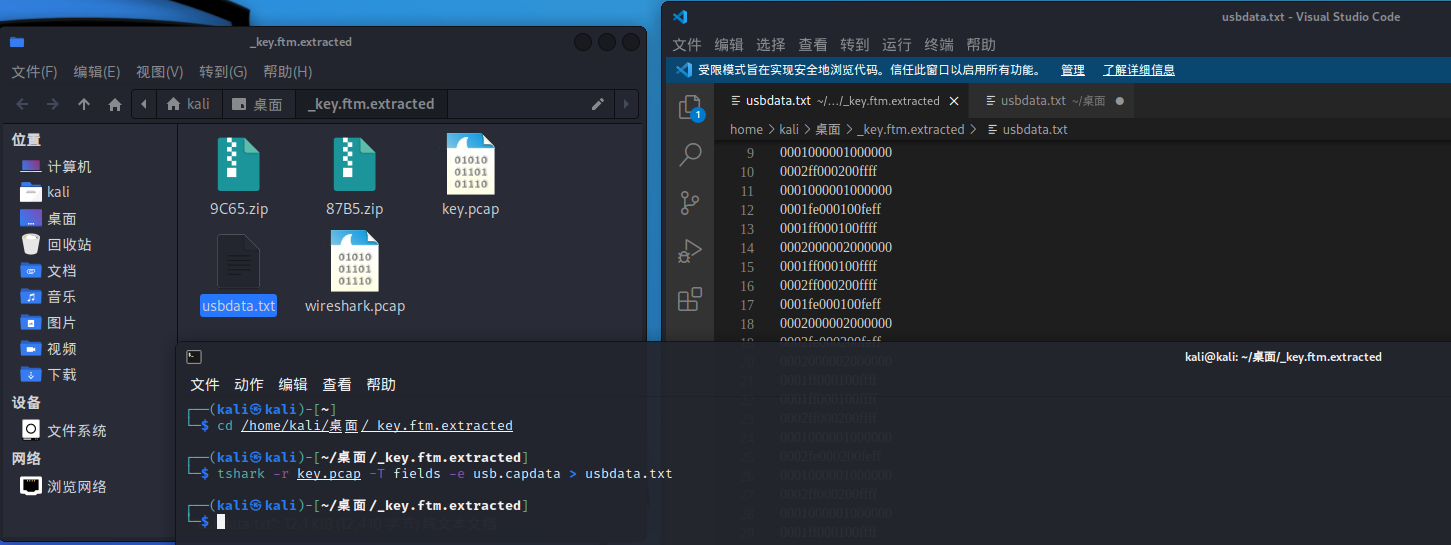 但是发现,我们得到的usbdata.txt中,数据之间没有冒号,然而很多脚本都是基于有冒号的情况编写的,于是我们使用脚本给数据之间加上冒号(或者想大佬一样使用Excel大佬的博客链接)
但是发现,我们得到的usbdata.txt中,数据之间没有冒号,然而很多脚本都是基于有冒号的情况编写的,于是我们使用脚本给数据之间加上冒号(或者想大佬一样使用Excel大佬的博客链接)
f=open('usbdata.txt','r')
fi=open('out.txt','w')
while 1:
a=f.readline().strip()
if a:
if len(a)==16: # 键盘流量的话len改为16
out=''
for i in range(0,len(a),2):
if i+2 != len(a):
out+=a[i]+a[i+1]+":"
else:
out+=a[i]+a[i+1]
fi.write(out)
fi.write('\n')
else:
break
fi.close()
mappings = { 0x04:"A", 0x05:"B", 0x06:"C", 0x07:"D", 0x08:"E", 0x09:"F", 0x0A:"G", 0x0B:"H", 0x0C:"I", 0x0D:"J", 0x0E:"K", 0x0F:"L", 0x10:"M", 0x11:"N",0x12:"O", 0x13:"P", 0x14:"Q", 0x15:"R", 0x16:"S", 0x17:"T", 0x18:"U",0x19:"V", 0x1A:"W", 0x1B:"X", 0x1C:"Y", 0x1D:"Z", 0x1E:"1", 0x1F:"2", 0x20:"3", 0x21:"4", 0x22:"5", 0x23:"6", 0x24:"7", 0x25:"8", 0x26:"9", 0x27:"0", 0x28:"\n", 0x2a:"[DEL]", 0X2B:" ", 0x2C:" ", 0x2D:"-", 0x2E:"=", 0x2F:"[", 0x30:"]", 0x31:"\\", 0x32:"~", 0x33:";", 0x34:"'", 0x36:",", 0x37:"." }
nums = []
keys = open('out.txt')
for line in keys:
if line[0]!='0' or line[1]!='0' or line[3]!='0' or line[4]!='0' or line[9]!='0' or line[10]!='0' or line[12]!='0' or line[13]!='0' or line[15]!='0' or line[16]!='0' or line[18]!='0' or line[19]!='0' or line[21]!='0' or line[22]!='0':
continue
nums.append(int(line[6:8],16))
keys.close()
output = ""
for n in nums:
if n == 0 :
continue
if n in mappings:
output += mappings[n]
else:
output += '[unknown]'
print 'output :\n' + output

鼠标流量
第一个字节,代表按键
当取0×00时,代表没有按键 当取0×01时,代表按左键 当取0×02时,代表当前按键为右键
第二个字节,可看作为signed byte类型,其最高位为符号位,
当值为正时,代表鼠标右移像素位; 值为负时,代表鼠标左移像素位。
第三个字节,代表垂直上下移动的偏移。
当值为正时,代表鼠标上移像素位; 值为负时,代表鼠标下移像素位。
第四个字节,代表扩展字节,鼠标有滚轮时才会激活
0x00, 未滚动 0x01,垂直向上滚动一次 0xFF,垂直向下滚动一次 0xFE,水平滚动左键单击一次 0x02,水平滚动右键单击一次
例题
拿到数据包,wireshark打开,使用tshark来提取数据
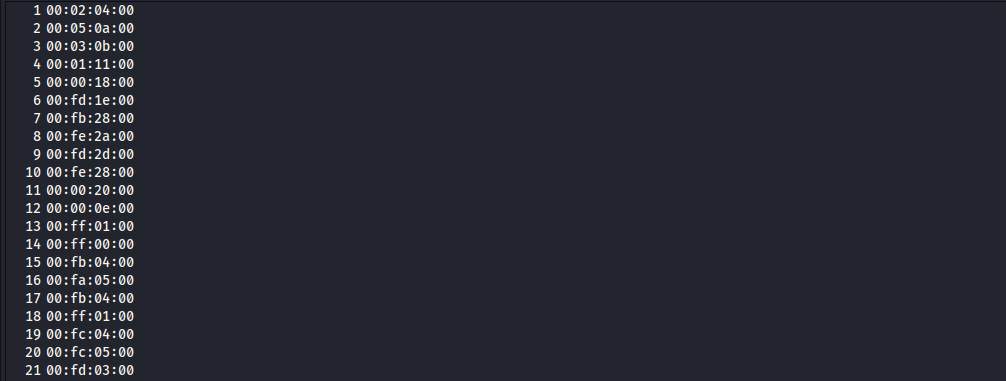
我们发现,有些数据明显不是鼠标的数据,推测应该是其他USB设备的数据。所以要进行一次过滤并加上冒号(代码与上文近似,只需修改len值为8)。
然后,使用鼠标流量脚本处理下(我们现在无法知道操作者是用左键还是右键进行鼠标移动,所以都需要测试一下,经测试发现为右键,即将btn_flag置为2)
nums = []
keys = open('out.txt','r')
f = open('xy.txt','w')
posx = 0
posy = 0
for line in keys:
if len(line) != 12 :
continue
x = int(line[3:5],16)
y = int(line[6:8],16)
if x > 127 :
x -= 256
if y > 127 :
y -= 256
posx += x
posy += y
btn_flag = int(line[0:2],16) # 1 for left , 2 for right , 0 for nothing
if btn_flag == 2 : # 1 代表左键
f.write(str(posx))
f.write(' ')
f.write(str(posy))
f.write('\n')
f.close()
然后得到的xy.txt中即为点的坐标
最后,我们使用gnuplot来绘制图形
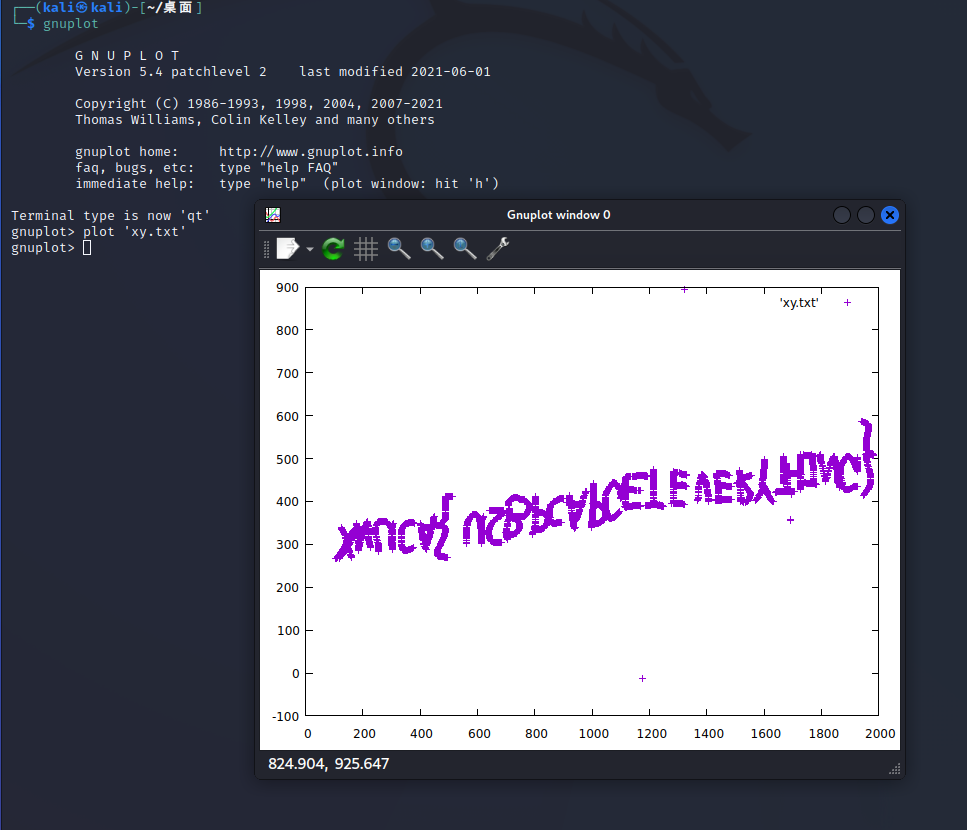 最后垂直翻转一下就行。
最后垂直翻转一下就行。
网络流量分析
例题
题目提示我们是有二维码,我们先了解一下二维码,有21×21的Version1,也有25×25的Version2……,二维码每个位置的色块用1位表示。(思路要往这方向靠)
我们打开流量包,发现有两条ARP协议以及122条ICMP协议。

 但ARP协议是解析IP为MAC的协议,故忽略,我们再看ICMP协议。
但ARP协议是解析IP为MAC的协议,故忽略,我们再看ICMP协议。
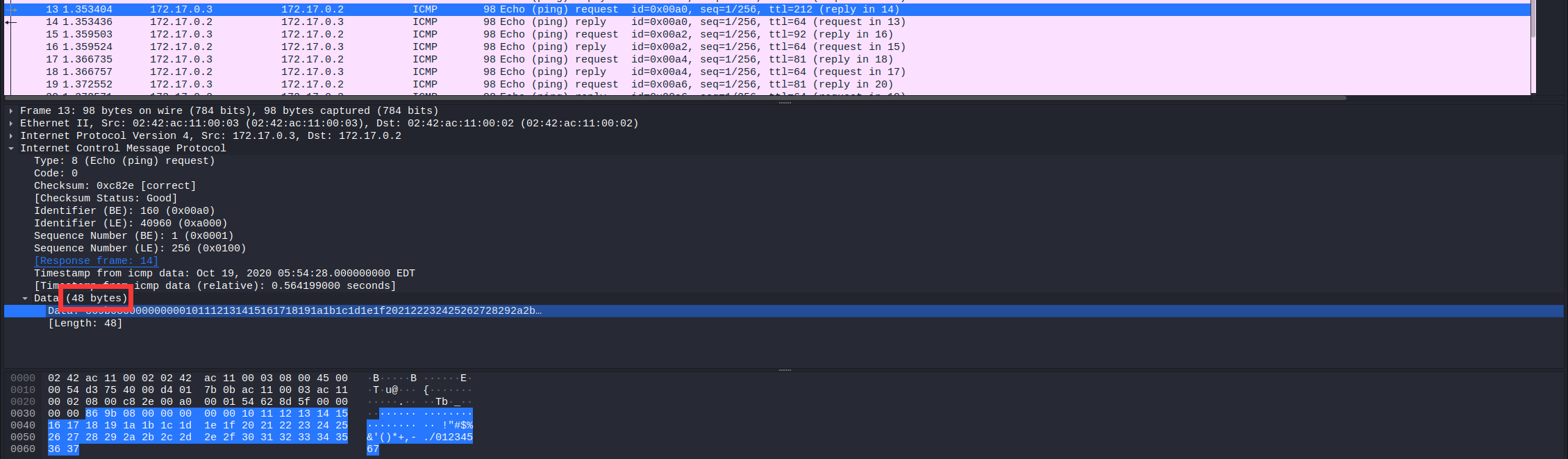 TTL的作用是限制IP数据包在计算机网络中的存在的时间(数值是0~2^8-1)。由于122条数据中包含发送和接收,事实上只有61条传输了我们需要的数据。我们再仔细观察,发现由172.17.0.2发送至172.17.0.3的TTL值都为64,怀疑其中没有传输二维码的数据。那么二维码的数据大概率是在后者发送给前者的数据包中了。
TTL的作用是限制IP数据包在计算机网络中的存在的时间(数值是0~2^8-1)。由于122条数据中包含发送和接收,事实上只有61条传输了我们需要的数据。我们再仔细观察,发现由172.17.0.2发送至172.17.0.3的TTL值都为64,怀疑其中没有传输二维码的数据。那么二维码的数据大概率是在后者发送给前者的数据包中了。
from PIL import Image
import os
data = ''
for i in os.popen('tshark -r wireshark.pcap -Y "icmp and ip.src == 172.17.0.3" -T fields -e "ip.ttl" | xargs').read()[:-1].split(' '):
data += bin(int(i))[2:].zfill(8)
w = 22
h = len(data) // 22 + 1
img = Image.new('1', (w, h), 255)
for i in range(len(data)):
img.putpixel((i % w, i // w), int(data[i]) * 255)
img.save('1.png')
得到1.png

评论区