



Unicorn初步学习
Unicorn介绍
●Q:Unicorn引擎是啥?
Unicorn Engine是一个轻量级, 多平台, 多架构的CPU模拟器框架,基于Qemu开发,它可以代替CPU模拟代码的执行,常用于程序虚拟、恶意代码分析、Fuzzing等,本项目被用于Qiling虚拟框架,Radare2逆向分析框架, GEF(gdb的pwn分析插件),Pwndbg,Angr符号执行框架等多个著名项目。
●Q:什么时候需要用到模拟执行器?
■你可以执行一些恶意软件中你感兴趣的函数而不必创建整个进程 ■CTF比赛中也很常用 ■Fuzzing ■GDB插件扩充,例如支持长跳转 ■模拟混淆后的代码
Unicorn的使用
0x01 导入模块并初始化
from unicorn import *
from unicorn.x86_const import *
uc = Uc(UC_ARCH_X86, UC_MODE_64)
#第一个参数:架构类型。这些常量以UC_ATCH_为前缀,第二个参数:架构细节说明。这些常量以UC_MODE_为前缀
#你可以在中文文档中找到说明
第一行代码会加载主要的二进制模块和一些Unicorn中的一些基本常量。 第二行加载了一些特定的x86和x64的常量。 第三行,创建一个实例
0x02 手动初始化内存,分配堆栈空间
设置地址
二进制文件的基址是0x400000。堆栈的话不妨从地址0x410000开始,大小为 2* 1024* 1024字节(2M),数据放在0x420000。
address = 0x400000 # 运行地址
stack_addr = 0x410000 # 堆栈地址
data_addr = 0x420000 # Data的数据
映射内存
使用mem_map函数来映射内存
uc.mem_map(address, 2 * 1024 * 1024) # 加载的地址与大小
0x03 内存读写
mem_read:第一个参数传递要读取的地址,第二个参数传递要读取的长度 mem_write第一个参数传递要写入的地址,第二个参数传递要写入的数据
uc.mem_write(address, Sub_code) # 将Sub_XXXX的代码数据写入运行地址
uc.mem_write(data_addr,Data)
0x04 寄存器的读写
uc_reg_write(寄存器,值) uc_reg_read(寄存器) E.g 模拟执行前 如加载器一样,已加载二进制文件到准备好的基址上来了。然后需要设置RSP指向我们申请的栈空间底部。
uc.reg_write(UC_X86_REG_ESP,stack_addr)
0x05 启动
uc.emu_start(Startaddr, Endaddr)
uc.emu_stop()
emu_start():来执行模拟,第一个参数填写模拟的开始地址,第二个参数填写模拟的结束地址 emu_stop:用来结束模拟
0x06 Hook(钩子)暂时还不会,以后补上
参考文献
[FlareOn4]greek_to_me复现
题目链接 这道题,有多种方法可以求解:Socket通信做法,Unicorn以及Angr
常规做法
查看main函数以及Socket函数内部
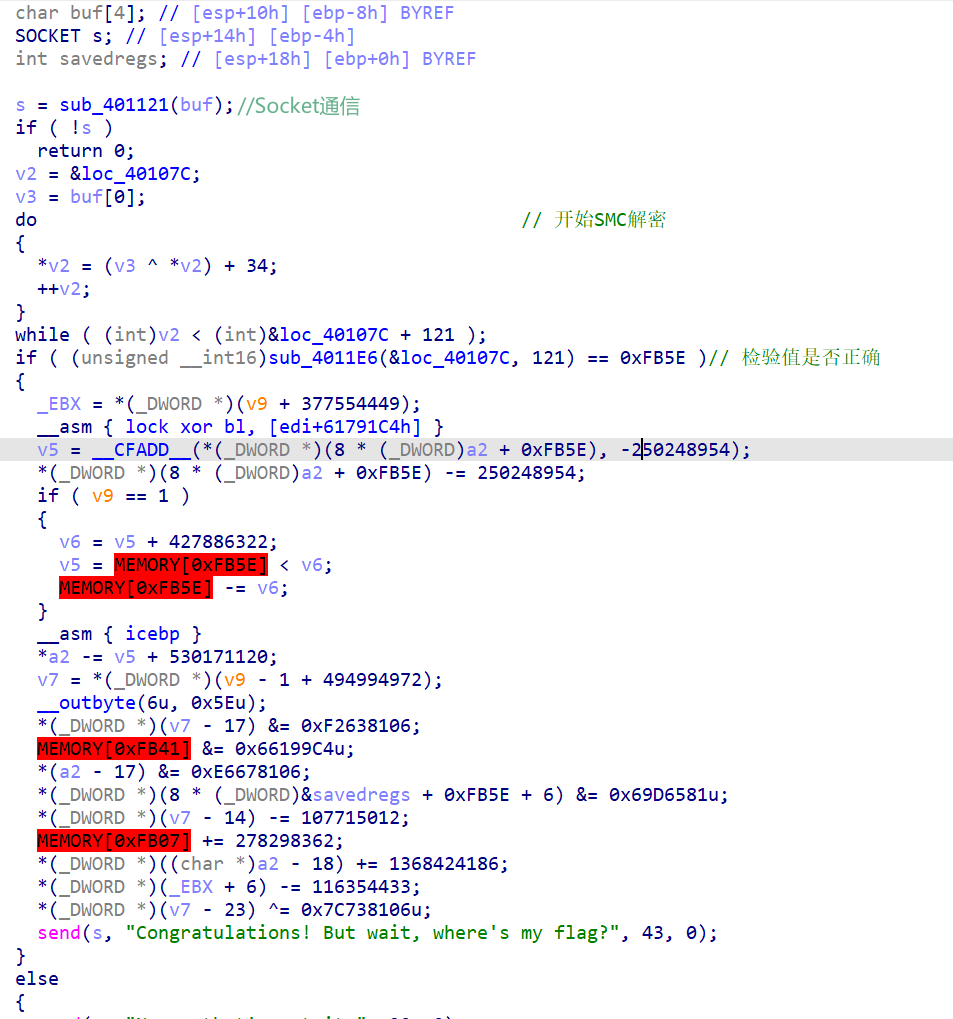
Main函数
Socket函数
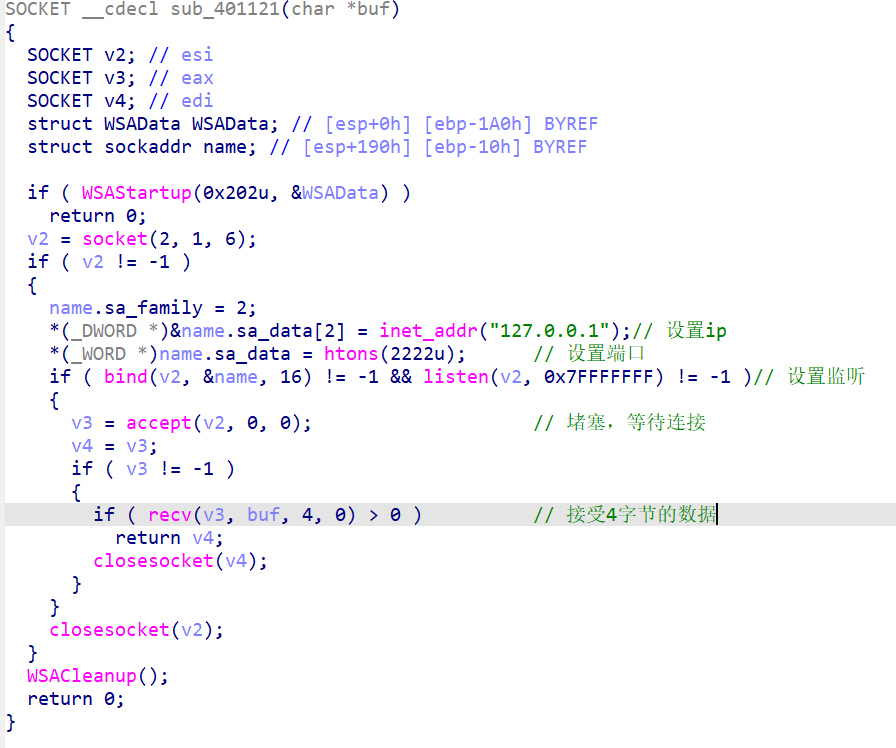
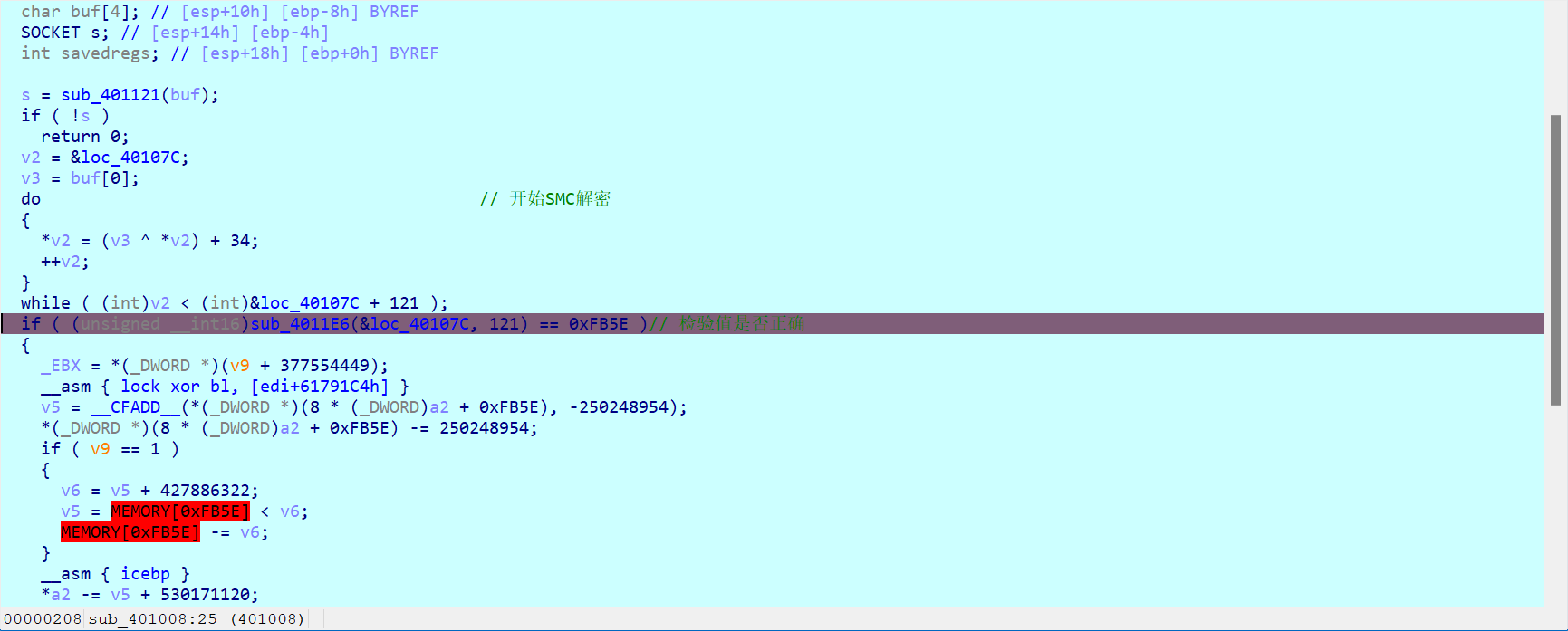
分析后,我们能知道程序的大致流程,先通过socket来建立通信,程序接收到两个字节(其实只用到一个字节(dl))的数据。接下来,对loc_40107C所存指令进行SMC解码(解码得到的指令有什么用呢?我们有理由怀疑其与flag有关),至于Sub_4011E6函数,是用来计算loc_40107c的校验值。
拿到buf的值
由于buf只有1个字节真正被用到,那么,我们可以爆破0~255,直到接收的反馈值包含Congratulation。
import sys
import socket
import os
ip='127.0.0.1'
port=2222
for i in range(256):
os.startfile("exe路径")
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect((ip,port))
s.send(chr(i).encode('latin1'))
data=s.recv(1024)
s.close()
if b'Congratulations' in data:
print(chr(i).encode('latin1'),' ',i,' ',data)
break
#编码为什么用latin1?有些编码对于ASC码大于128的字符,会用2个Bytes表示,一开始就是因为这个问题,导致发送时\xa2变成\xc2\xa2。而采用1个Byte固定大小编码的encoding,比如ISO 8859-1,又称latin1。
需要爆破挺久的。
 得到值后,我们开始调试。
得到值后,我们开始调试。
Debug2GetFlag
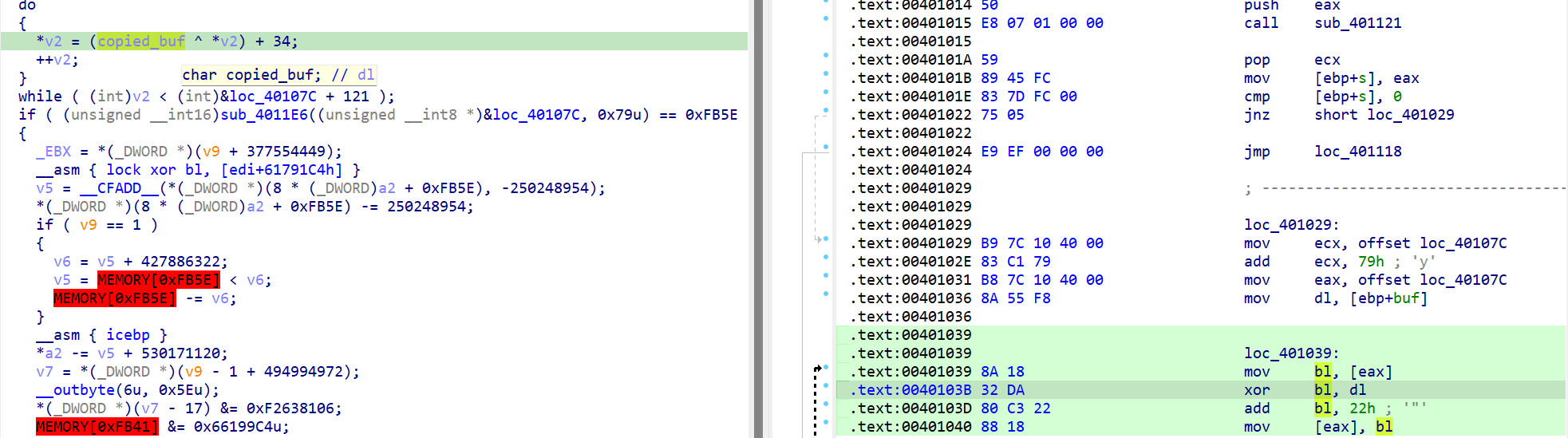
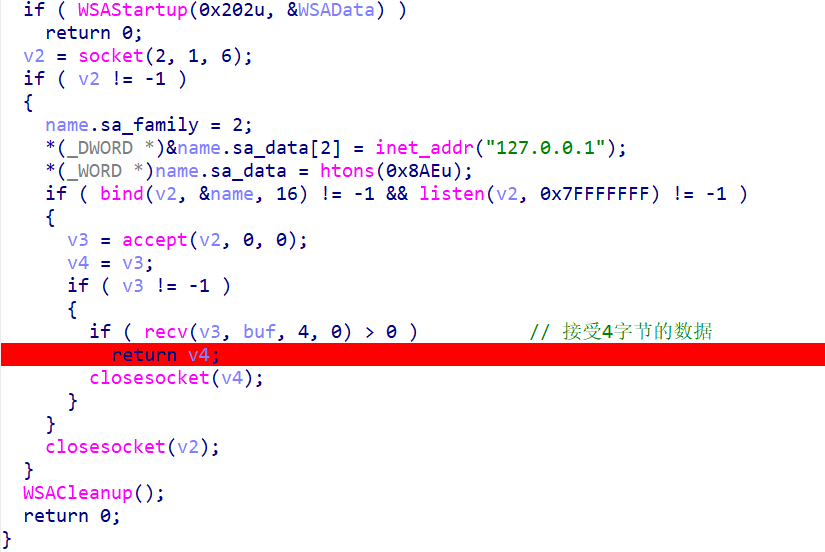 此处下断点后,开始调试,发送buf值
此处下断点后,开始调试,发送buf值
import os
import socket
import sys
import socket
import os
ip='127.0.0.1'
port=2222
os.startfile("exe路径")
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect((ip,port))
s.send(chr(162).encode('latin1'))
s.close()
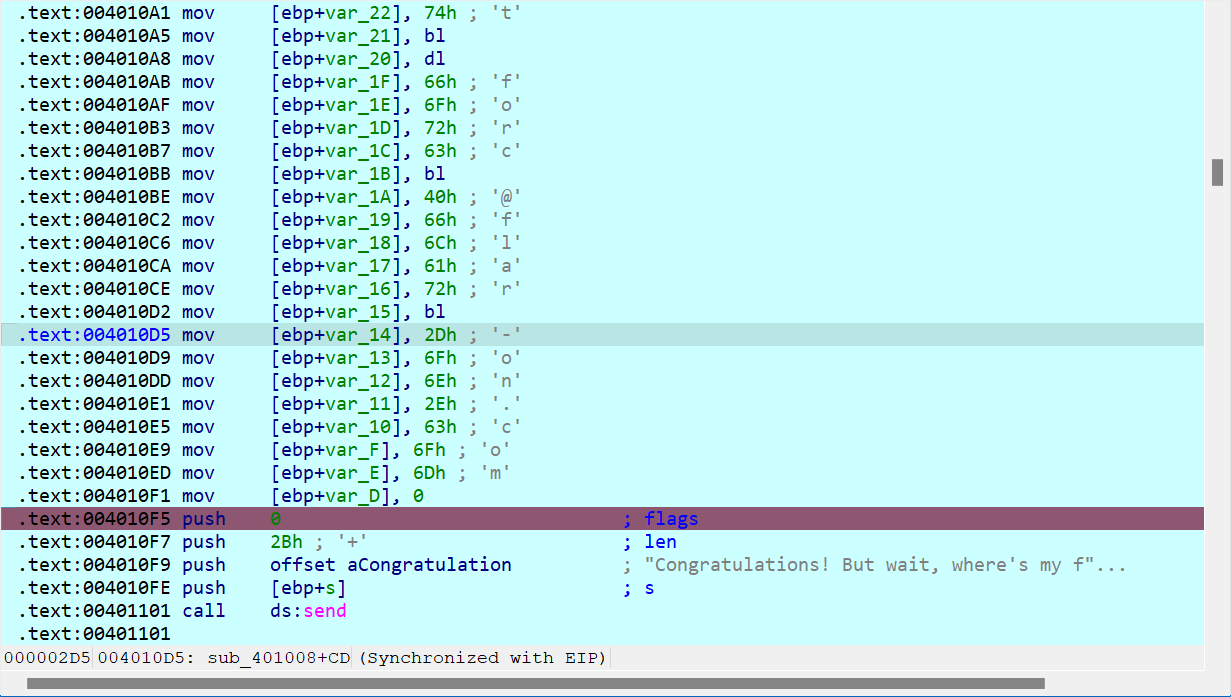
 直接运行到SMC解码结束处,然后查看loc_40107c的值
直接运行到SMC解码结束处,然后查看loc_40107c的值
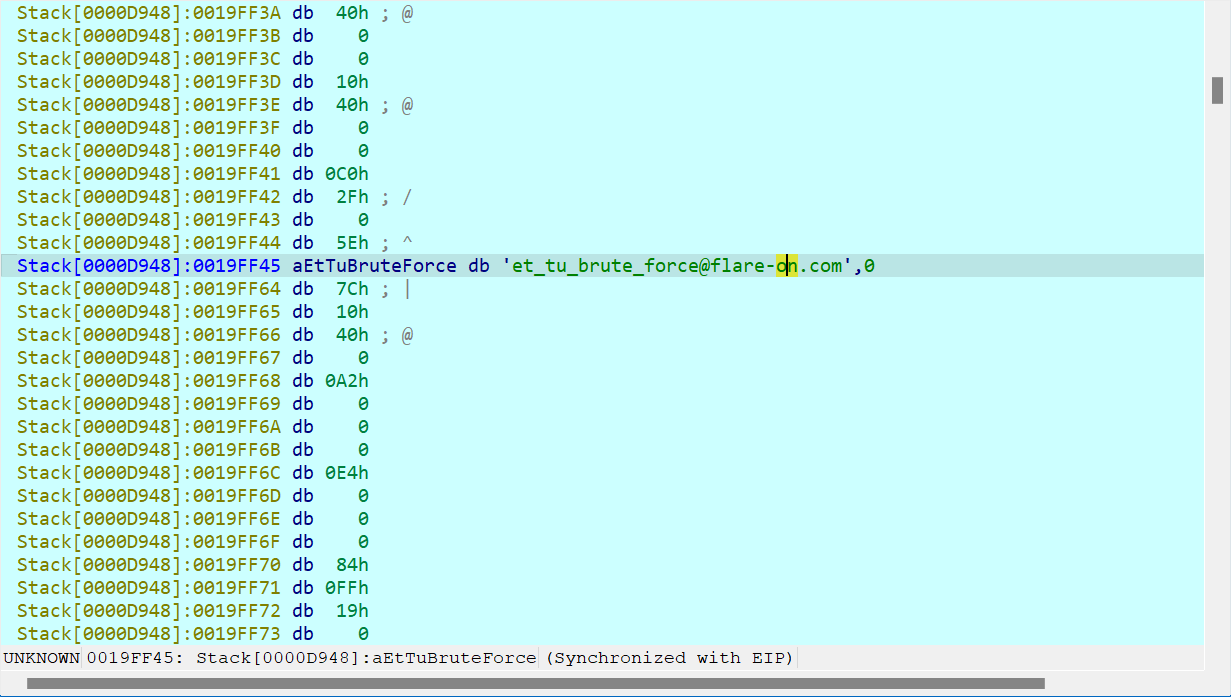
 先U后P,然后在指令的末端下断点,F9运行到mov指令结束,那么我们就能在堆栈中找到flag!!!完结✿✿ヽ(°▽°)ノ✿
先U后P,然后在指令的末端下断点,F9运行到mov指令结束,那么我们就能在堆栈中找到flag!!!完结✿✿ヽ(°▽°)ノ✿
Unicorn模拟执行做法
部分参考 Vancir的译文 P.Z ‘s Blog
大致思路
主要是模拟Sub_4011E6函数,然后计算loc_40107c的检验值,如果最后的检验值等于0xfb5e,那么我们就可以反汇编loc_40107c的值,得到正确的指令。
0x01 提取loc_40107c以及Sub_4011e6的值(推荐使用lazyIDA插件)
check_code_origin=[ 0x55, 0x8B, 0xEC, 0x51, 0x8B, 0x55, 0x0C, 0xB9, 0xFF, 0x00, 0x00, 0x00, 0x89, 0x4D, 0xFC, 0x85,
0xD2, 0x74, 0x51, 0x53, 0x8B, 0x5D, 0x08, 0x56, 0x57, 0x6A, 0x14, 0x58, 0x66, 0x8B, 0x7D, 0xFC,
0x3B, 0xD0, 0x8B, 0xF2, 0x0F, 0x47, 0xF0, 0x2B, 0xD6, 0x0F, 0xB6, 0x03, 0x66, 0x03, 0xF8, 0x66,
0x89, 0x7D, 0xFC, 0x03, 0x4D, 0xFC, 0x43, 0x83, 0xEE, 0x01, 0x75, 0xED, 0x0F, 0xB6, 0x45, 0xFC,
0x66, 0xC1, 0xEF, 0x08, 0x66, 0x03, 0xC7, 0x0F, 0xB7, 0xC0, 0x89, 0x45, 0xFC, 0x0F, 0xB6, 0xC1,
0x66, 0xC1, 0xE9, 0x08, 0x66, 0x03, 0xC1, 0x0F, 0xB7, 0xC8, 0x6A, 0x14, 0x58, 0x85, 0xD2, 0x75,
0xBB, 0x5F, 0x5E, 0x5B, 0x0F, 0xB6, 0x55, 0xFC, 0x8B, 0xC1, 0xC1, 0xE1, 0x08, 0x25, 0x00, 0xFF,
0x00, 0x00, 0x03, 0xC1, 0x66, 0x8B, 0x4D, 0xFC, 0x66, 0xC1, 0xE9, 0x08, 0x66, 0x03, 0xD1, 0x66,
0x0B, 0xC2]
check_code=b''
for i in check_code_origin:
check_code+=(i).to_bytes(1,'little')#小端序
Encode_bytes=[ 0x33, 0xE1, 0xC4, 0x99, 0x11, 0x06, 0x81, 0x16, 0xF0, 0x32, 0x9F, 0xC4, 0x91, 0x17, 0x06, 0x81,
0x14, 0xF0, 0x06, 0x81, 0x15, 0xF1, 0xC4, 0x91, 0x1A, 0x06, 0x81, 0x1B, 0xE2, 0x06, 0x81, 0x18,
0xF2, 0x06, 0x81, 0x19, 0xF1, 0x06, 0x81, 0x1E, 0xF0, 0xC4, 0x99, 0x1F, 0xC4, 0x91, 0x1C, 0x06,
0x81, 0x1D, 0xE6, 0x06, 0x81, 0x62, 0xEF, 0x06, 0x81, 0x63, 0xF2, 0x06, 0x81, 0x60, 0xE3, 0xC4,
0x99, 0x61, 0x06, 0x81, 0x66, 0xBC, 0x06, 0x81, 0x67, 0xE6, 0x06, 0x81, 0x64, 0xE8, 0x06, 0x81,
0x65, 0x9D, 0x06, 0x81, 0x6A, 0xF2, 0xC4, 0x99, 0x6B, 0x06, 0x81, 0x68, 0xA9, 0x06, 0x81, 0x69,
0xEF, 0x06, 0x81, 0x6E, 0xEE, 0x06, 0x81, 0x6F, 0xAE, 0x06, 0x81, 0x6C, 0xE3, 0x06, 0x81, 0x6D,
0xEF, 0x06, 0x81, 0x72, 0xE9, 0x06, 0x81, 0x73,0x7c]
encode_bytes=b''
for i in Encode_bytes:
encode_bytes+=(i).to_bytes(1,'little')#小端序
0x02.SMC解码函数
def decode_bytes(i):
decoded_bytes=[]
for j in encode_bytes:
decoded_bytes.append(((i^j)+34)&0xff)
return bytes(decoded_bytes)
模拟执行的代码
def checksum(decoded_bytes):
address=0x400000
stack_addr=0x410000
decode_bytes_addr=0x420000
#设置启动的框架以及其的位数
uc = Uc(UC_ARCH_X86,UC_MODE_32)
uc.mem_map(address,2*1024*1024)
#内存映射,mem_map:第一个参数传递要映射的地址,第二个参数传递要映射的长度(按页对齐)。
uc.mem_write(address,check_code)
uc.mem_write(decode_bytes_addr,decoded_bytes)
#第一个参数传递要写入的地址,第二个参数传递要写入的数据
uc.reg_write(UC_X86_REG_ESP,stack_addr)#寄存器读写
uc.mem_write(stack_addr+4,struct.pack('<i',decode_bytes_addr))#设置Sub_4011e6的参数
uc.mem_write(stack_addr+8,struct.pack('<i',0x79))#设置Sub_4011e6的参数
uc.emu_start(address,address+len(check_code))
#emu_start:来执行模拟,第一个参数填写模拟的开始地址,第二个参数填写模拟的结束地址
checksumed=uc.reg_read(UC_X86_REG_AX) # 读取结果,注意最后的返回值在ax中,可以在IDA的汇编窗口中看到
return checksumed
Capstone输出正确的反汇编的loc_0x40107c指令
for i in range(256):
decoded_bytes=decode_bytes(i)
checkedsum=checksum(decoded_bytes)
if checkedsum==0xfb5e:
print('Checksum matched with byte %X' % i)
print('Decoded bytes disassembly:')
md = Cs(CS_ARCH_X86, CS_MODE_32)
for j in md.disasm(decoded_bytes, 0):#第二个参数指的是读取 raw 二进制数据的起始地址 , 一般设置 0 即可
print("0x%x:\t%s\t%s" % (j.address, j.mnemonic, j.op_str))
flag=''
for j in md.disasm(decoded_bytes,0):
flag_char=''
try:
if j.op_str.split(',')[0].startswith("byte ptr"):
flag_char = chr(int(j.op_str.split(',')[1], 16))
if j.op_str.split(',')[0].startswith('bl'):
bl = chr(int(j.op_str.split(',')[1], 16))
if j.op_str.split(',')[0].startswith('dl'):
dl = chr(int(j.op_str.split(',')[1], 16))
except:
if j.op_str.split(',')[1].strip() == 'dl':
flag_char = dl
if j.op_str.split(',')[1].strip() == 'bl':
flag_char = bl
if (flag_char):
flag+=(flag_char.strip())
print(flag)
break
得到flag
from unicorn import *
from unicorn.x86_const import *
from capstone import *
import struct
import re
check_code_origin=[ 0x55, 0x8B, 0xEC, 0x51, 0x8B, 0x55, 0x0C, 0xB9, 0xFF, 0x00, 0x00, 0x00, 0x89, 0x4D, 0xFC, 0x85,
0xD2, 0x74, 0x51, 0x53, 0x8B, 0x5D, 0x08, 0x56, 0x57, 0x6A, 0x14, 0x58, 0x66, 0x8B, 0x7D, 0xFC,
0x3B, 0xD0, 0x8B, 0xF2, 0x0F, 0x47, 0xF0, 0x2B, 0xD6, 0x0F, 0xB6, 0x03, 0x66, 0x03, 0xF8, 0x66,
0x89, 0x7D, 0xFC, 0x03, 0x4D, 0xFC, 0x43, 0x83, 0xEE, 0x01, 0x75, 0xED, 0x0F, 0xB6, 0x45, 0xFC,
0x66, 0xC1, 0xEF, 0x08, 0x66, 0x03, 0xC7, 0x0F, 0xB7, 0xC0, 0x89, 0x45, 0xFC, 0x0F, 0xB6, 0xC1,
0x66, 0xC1, 0xE9, 0x08, 0x66, 0x03, 0xC1, 0x0F, 0xB7, 0xC8, 0x6A, 0x14, 0x58, 0x85, 0xD2, 0x75,
0xBB, 0x5F, 0x5E, 0x5B, 0x0F, 0xB6, 0x55, 0xFC, 0x8B, 0xC1, 0xC1, 0xE1, 0x08, 0x25, 0x00, 0xFF,
0x00, 0x00, 0x03, 0xC1, 0x66, 0x8B, 0x4D, 0xFC, 0x66, 0xC1, 0xE9, 0x08, 0x66, 0x03, 0xD1, 0x66,
0x0B, 0xC2]
check_code=b''
for i in check_code_origin:
check_code+=(i).to_bytes(1,'little')
Encode_bytes=[ 0x33, 0xE1, 0xC4, 0x99, 0x11, 0x06, 0x81, 0x16, 0xF0, 0x32, 0x9F, 0xC4, 0x91, 0x17, 0x06, 0x81,
0x14, 0xF0, 0x06, 0x81, 0x15, 0xF1, 0xC4, 0x91, 0x1A, 0x06, 0x81, 0x1B, 0xE2, 0x06, 0x81, 0x18,
0xF2, 0x06, 0x81, 0x19, 0xF1, 0x06, 0x81, 0x1E, 0xF0, 0xC4, 0x99, 0x1F, 0xC4, 0x91, 0x1C, 0x06,
0x81, 0x1D, 0xE6, 0x06, 0x81, 0x62, 0xEF, 0x06, 0x81, 0x63, 0xF2, 0x06, 0x81, 0x60, 0xE3, 0xC4,
0x99, 0x61, 0x06, 0x81, 0x66, 0xBC, 0x06, 0x81, 0x67, 0xE6, 0x06, 0x81, 0x64, 0xE8, 0x06, 0x81,
0x65, 0x9D, 0x06, 0x81, 0x6A, 0xF2, 0xC4, 0x99, 0x6B, 0x06, 0x81, 0x68, 0xA9, 0x06, 0x81, 0x69,
0xEF, 0x06, 0x81, 0x6E, 0xEE, 0x06, 0x81, 0x6F, 0xAE, 0x06, 0x81, 0x6C, 0xE3, 0x06, 0x81, 0x6D,
0xEF, 0x06, 0x81, 0x72, 0xE9, 0x06, 0x81, 0x73,0x7c]
encode_bytes=b''
for i in Encode_bytes:
encode_bytes+=(i).to_bytes(1,'little')
def decode_bytes(i):
decoded_bytes=[]
for j in encode_bytes:
decoded_bytes.append(((i^j)+34)&0xff)
return bytes(decoded_bytes)
def checksum(decoded_bytes):
address=0x400000
stack_addr=0x410000
decode_bytes_addr=0x420000
#设置启动的框架以及其的位数
uc = Uc(UC_ARCH_X86,UC_MODE_32)
uc.mem_map(address,2*1024*1024)
#内存映射,mem_map:第一个参数传递要映射的地址,第二个参数传递要映射的长度(按页对齐)。
uc.mem_write(address,check_code)
uc.mem_write(decode_bytes_addr,decoded_bytes)
#第一个参数传递要写入的地址,第二个参数传递要写入的数据
uc.reg_write(UC_X86_REG_ESP,stack_addr)#寄存器读写
uc.mem_write(stack_addr+4,struct.pack('<i',decode_bytes_addr))#设置Sub_4011e6的参数
uc.mem_write(stack_addr+8,struct.pack('<i',0x79))#设置Sub_4011e6的参数
uc.emu_start(address,address+len(check_code))
#emu_start:来执行模拟,第一个参数填写模拟的开始地址,第二个参数填写模拟的结束地址
checksumed=uc.reg_read(UC_X86_REG_AX) # 读取结果,注意最后的返回值在ax中,可以在IDA的汇编窗口中看到
return checksumed
for i in range(256):
decoded_bytes=decode_bytes(i)
checkedsum=checksum(decoded_bytes)
if checkedsum==0xfb5e:
print('Checksum matched with byte %X' % i)
print('Decoded bytes disassembly:')
md = Cs(CS_ARCH_X86, CS_MODE_32)
for j in md.disasm(decoded_bytes, 0):#第二个参数指的是读取 raw 二进制数据的起始地址 , 一般设置 0 即可
print("0x%x:\t%s\t%s" % (j.address, j.mnemonic, j.op_str))
flag=''
for j in md.disasm(decoded_bytes,0):
flag_char=''
try:
if j.op_str.split(',')[0].startswith("byte ptr"):
flag_char = chr(int(j.op_str.split(',')[1], 16))
if j.op_str.split(',')[0].startswith('bl'):
bl = chr(int(j.op_str.split(',')[1], 16))
if j.op_str.split(',')[0].startswith('dl'):
dl = chr(int(j.op_str.split(',')[1], 16))
except:
if j.op_str.split(',')[1].strip() == 'dl':
flag_char = dl
if j.op_str.split(',')[1].strip() == 'bl':
flag_char = bl
if (flag_char):
flag+=(flag_char.strip())
print(flag)
break
PrintFlag
Checksum matched with byte A2
Decoded bytes disassembly:
0x0: mov bl, 0x65
0x2: mov byte ptr [ebp - 0x2b], bl
0x5: mov byte ptr [ebp - 0x2a], 0x74
0x9: mov dl, 0x5f
0xb: mov byte ptr [ebp - 0x29], dl
0xe: mov byte ptr [ebp - 0x28], 0x74
0x12: mov byte ptr [ebp - 0x27], 0x75
0x16: mov byte ptr [ebp - 0x26], dl
0x19: mov byte ptr [ebp - 0x25], 0x62
0x1d: mov byte ptr [ebp - 0x24], 0x72
0x21: mov byte ptr [ebp - 0x23], 0x75
0x25: mov byte ptr [ebp - 0x22], 0x74
0x29: mov byte ptr [ebp - 0x21], bl
0x2c: mov byte ptr [ebp - 0x20], dl
0x2f: mov byte ptr [ebp - 0x1f], 0x66
0x33: mov byte ptr [ebp - 0x1e], 0x6f
0x37: mov byte ptr [ebp - 0x1d], 0x72
0x3b: mov byte ptr [ebp - 0x1c], 0x63
0x3f: mov byte ptr [ebp - 0x1b], bl
0x42: mov byte ptr [ebp - 0x1a], 0x40
0x46: mov byte ptr [ebp - 0x19], 0x66
0x4a: mov byte ptr [ebp - 0x18], 0x6c
0x4e: mov byte ptr [ebp - 0x17], 0x61
0x52: mov byte ptr [ebp - 0x16], 0x72
0x56: mov byte ptr [ebp - 0x15], bl
0x59: mov byte ptr [ebp - 0x14], 0x2d
0x5d: mov byte ptr [ebp - 0x13], 0x6f
0x61: mov byte ptr [ebp - 0x12], 0x6e
0x65: mov byte ptr [ebp - 0x11], 0x2e
0x69: mov byte ptr [ebp - 0x10], 0x63
0x6d: mov byte ptr [ebp - 0xf], 0x6f
0x71: mov byte ptr [ebp - 0xe], 0x6d
0x75: mov byte ptr [ebp - 0xd], 0
e
et
et
et_
et_t
et_tu
et_tu_
et_tu_b
et_tu_br
et_tu_bru
et_tu_brut
et_tu_brute
et_tu_brute_
et_tu_brute_f
et_tu_brute_fo
et_tu_brute_for
et_tu_brute_forc
et_tu_brute_force
et_tu_brute_force@
et_tu_brute_force@f
et_tu_brute_force@fl
et_tu_brute_force@fla
et_tu_brute_force@flar
et_tu_brute_force@flare
et_tu_brute_force@flare-
et_tu_brute_force@flare-o
et_tu_brute_force@flare-on
et_tu_brute_force@flare-on.
et_tu_brute_force@flare-on.c
et_tu_brute_force@flare-on.co
et_tu_brute_force@flare-on.com
et_tu_brute_force@flare-on.com
完结✿✿ヽ(°▽°)ノ✿
评论区